记录提取网页数据(正则表达式、bs4、xpath)一些常用方法和使用样板。
就永恒君使用经验来说,bs4、xpath比较容易上手但是功能有限,正则比较晦涩难懂但是功能超级强大。
简介
正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
re 模块使 Python 语言拥有全部的正则表达式功能。
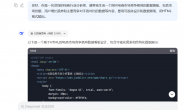
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('runoob 123')
##结果为123,类型为list
或者
import re
result1=re.findall(r'\d+','runoob 123')
具体怎么写正则表达式就不多说了,这里有一个教程可以参考:https://github.com/ziishaned/learn-regex/blob/master/translations/README-cn.md
网上教程也很多,多写多练才能更好掌握。
bs4
之前介绍了用bs4来解析 html 标签,完成之后就可以调用bs4的各种方法来提取数据。
基本用法
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'lxml')
soup.prettify() #格式化网页代码,缺少的补齐等等
soup.title #获取<title>标签
soup.title.string #获取title的文本内容
soup.p #获取p标签
soup.p["class"] #获取p标签的class属性
soup.find_all('a') #返回所有的a标签,返回列表
更多详细看官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
xpath
简单来说,xpath 就是一种在 XML 文档中查找信息的语言。
基本用法
test = html.xpath('/html/head/title') #表示匹配根节点下的head节点下的title元素节点
test = html.xpath('/html/head/title/text()')#表示匹配根节点下的head节点下的title元素节点中的文本节点
test = html.xpath('/a/@href') #表示匹配a元素节点下的子节点中的 href 属性节点
test = html.xpath('//a[@href]') #匹配带有 href 属性的 <a> 标签
test = html.xpath('//a[@href="image1.html"]') #指定带有 href 属性且值为 image1.html 的 <a> 标签
xpath 方法返回字符串或者匹配列表,匹配列表中的每一项都是 lxml.etree._Element 对象。
如上面的 test 作为测试样例,test 中的每一项都是一个 _Element 对象。我们写爬虫最终获取的数据信息,就是通过_Element 对象的方法来获取的。
test = html.xpath('//a[@href="image1.html"]')
obj = test[0]
obj.tag #返回标签名'a'
obj.attrib #返回属性与值组成的字典{'href': 'image1.html'}
obj.get('href') #返回指定属性的值
obj.text #返回文本值
使用XPath有一个方便的地方在于,可以直接使用Chrome浏览器来获取XPath路径,方法是:在网页中右击->选择审查元素(或者使用F12打开) 就可以在elements中查看网页的html标签了,找到你想要获取XPath的标签,右击->Copy XPath 就已经将XPath路径复制到了剪切板。

常用的样板
正则
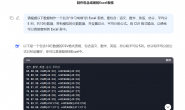
import requests
import re#导入相关的库
url="https://www.yhjbox.com"
data = requests.get(url)
pattern = re.compile(r'<title>(.*?)</title>') # 查找数字
title = pattern.findall(data.text)
print(title)

bs4
from bs4 import BeautifulSoup
import lxml
import requests
url='https://www.yhjbox.com'
data = requests.get(url)
soup = BeautifulSoup(data.content, 'lxml')
title = soup.find_all('title')[0].string
print(title)

xpath
import requests
from lxml import etree
url = 'https://www.yhjbox.com'
data = requests.get(url)
html = etree.HTML(data.text)
title = html.xpath('/html/head/title/text()')
print(title)

python爬虫系列(3)- 网页数据解析(bs4、lxml、Json库)
python实例:
用python定制网页跟踪神器,有信息更新第一时间通知你(附视频演示)
微信公众号:永恒君的百宝箱
个人博客:www.yhjbox.com