今天继续记录一下python的一个实例-定制批量获取智联招聘的信息。
也是应了一个大学同学的需求,他在PCB行业浸淫了10几年,有了一定的基础和实力时候,开始准备自己干一番大事业,祝他一帆风顺,马到成功!
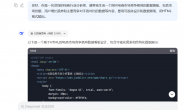
前段时间和我讲,希望可以快速的获取到大量的行业相关公司的信息。他给我打了个比方,如下图,在智联招聘上面搜索电子工程师后,会有好多相关职位、公司信息,挨个点进去,就能获取到红框内的内容。


但是,挨个点,复制-粘贴,这个效率太低了。
他希望说,快速批量爬取所需要的信息,并且保存下来。
说实话,这个功能需求很简单,永恒君在网上也看到了好多的大神都写过相关的教程和代码,比这个需求更高级、更完善。
但是,高级、功能多意味着代码量也更大,需要学习和调试的工作量也是非常大。
本着解决问题的原则,永恒君借鉴了一下大神的教程和思路,写了一个简单粗暴,但是有效的代码。
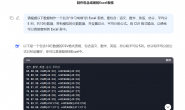
先上效果,以“深圳”、“layout”这个关键词为例,搜索部分结果如下:

程序爬取后结果如下图:

操作过程视频:
主要是把问题按如下分解:
1、获取职位链接目录
即网站搜索关键词之后,出来的职位列表。将职位名称,链接以字典的形式保存到url_list数组当中。
def get_urls(start,cityname,jobname):#获取职位的链接目录
url_list=[]#保存职位链接
for i in range(start):
url = 'https://fe-api.zhaopin.com/c/i/sou?start='+str(i*90)+'&pageSize=90&cityId='+str(cityname)+'&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw='+parse.quote(str(jobname))+'&kt=3'
#start设置翻页,默认起始页为0,第二页为90,第三页为180,以此类推;
#cityname为城市名,可用代码,也可以用城市首字母,如深圳,'sz'。建议用代码,更准确,如全国-489,北京-530,上海-538,深圳-765,广州-763,天津-531。
#jobname为职位名,中英文都可以
try:
rec = requests.get(url=url,headers=headers)
if rec.status_code == 200:
j = json.loads(rec.text)
results = j.get('data').get('results')
for job in results:
url_dict = {
'positionURL':job.get('positionURL'),#公司职位链接
'Job_name':job.get('jobName')#职位名称
}
url_list.append(url_dict)
except:
print("maybe error")
pass
return url_list
2、获取职位的详细信息
即模拟点击上面获取的职位链接,提取所需要的信息,如公司名称、职位名称、职位描述、工作地点、薪资等等,以字典的形式保存。
def get_job(url):#获取职位的详细信息
try:
res = requests.get(url)
html = res.text
soup = bs(html, "lxml")
job_dict = {"company_name":soup.find_all('a',class_="company__title")[0].text,#公司名称
"job_name":soup.find_all('h3',class_="summary-plane__title")[0].text,#职位名称
"job_des":soup.find_all('div',class_="describtion__detail-content")[0].text,#职位描述
"job_location":soup.find_all('span',class_="job-address__content-text")[0].text,#职位工作地点
"salary":soup.find_all('span',class_="summary-plane__salary")[0].text,#薪资
}
return job_dict
except:
pass
return None
3、将获取到的信息保存到excel表当中
f = xlwt.Workbook() #创建工作簿
sheet1 = f.add_sheet(u'jobs',cell_overwrite_ok=True) #创建sheet,可写
headers = (['公司名称'],['职位名称'],['职位描述'],['工作地点'],['薪资'],['职位链接'])#写表头
j=0
for each_header in headers:
sheet1.write(0,j,each_header)#参数对应行 列 值
j=j+1
#写内容
hang=1
lie=0
for i in get_urls(pages,city,job_keyword):#逐行写入内容
job = get_job(i['positionURL'])#job_dic
print("正在获取: "+job['job_name']+" 职位信息")
print('正在写入信息...')
sheet1.write(hang,lie,job['company_name'])#参数对应行 列 值,写入公司名称
sheet1.write(hang,lie+1,job['job_name'])#写入职位名称
sheet1.write(hang,lie+2,job['job_des'])#写入职位描述
sheet1.write(hang,lie+3,job['job_location'])#写入工作地点
sheet1.write(hang,lie+4,job['salary'])#写入薪资
sheet1.write(hang,lie+5,i['positionURL'])#写入职位链接
print('写入完毕')
hang=hang+1
f.save('jobs.xls')#保存文件
4、简单优化代码
上面三部分组合起来程序已经可以运行了,为了更好的使用,做了一点点的优化。
给程序添加一些请求的头,目的是模拟人工真实访问,迷惑网站服务器。
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'fe-api.zhaopin.com',
'Origin':'https://sou.zhaopin.com',
'Referer':'https://sou.zhaopin.com/?p=3&jl=765&sf=0&st=0&kw=pcb&kt=3',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
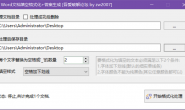
添加一些和程序互动的界面
city = input("请输入查找的城市id,如全国-489,北京-530,上海-538,深圳-765,广州-763,天津-531:")
job_keyword = input("请输入查找的职位关键词,如pcb:")
pages = int(input("请输入需要查找的页数(1-9):"))
print("正在获取: "+job['job_name']+" 职位信息")
print('正在写入信息...')
print('所有信息写入完毕')
代码简单,主要是给新人以解决问题、实用为主。
后续如果有必要当然可以添加诸如多线程、图形化界面、防反爬、封装等功能,可以再进一步提高效率。
欢迎有需要的伙伴测试,大咖们多多指点!
转载请注明:永恒君的百宝箱 » Python帮你定制批量获取智联招聘的信息