大家好,我是爱分享的永恒君!
之前分享过如何来快速搜集百度搜索的结果,文章在这里:… Read the rest

大家好,我是爱分享的永恒君!
之前分享过如何来快速搜集百度搜索的结果,文章在这里:… Read the rest
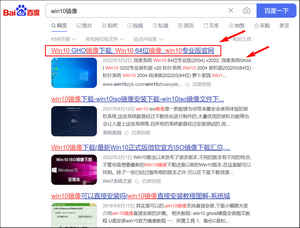
大家好,我是爱分享的永恒君!
最新因为数据分析的原因,需要采集一些关键词在百度的搜索结果。… Read the rest
新浪微博评论的数据一直是不少做数据分析朋友感兴趣的内容之一,但是获取数据本身可能就难到了不少人。
其实这个用之前介绍的web … Read the rest
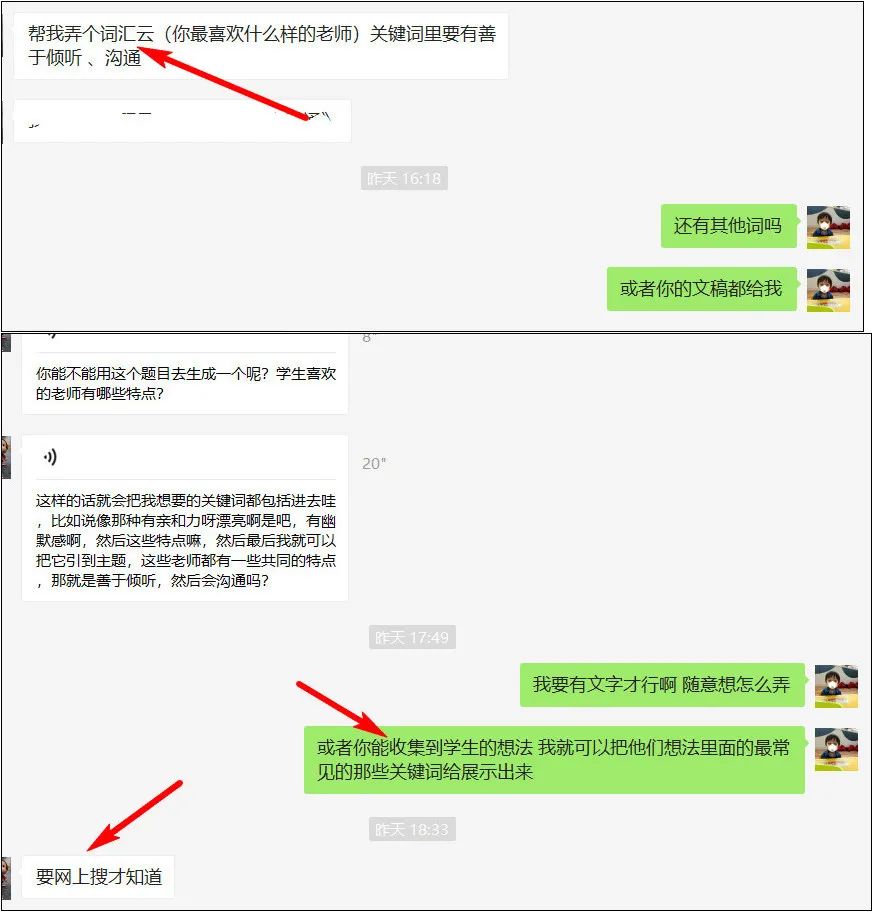 要制作词云呢,需要有一定数量的… Read the rest
要制作词云呢,需要有一定数量的… Read the rest 
webscraper就可以帮我们快速的建立这样的目录。
… Read the rest 做数据分析,首先要有数据来源。以最近热门的关键词… Read the rest
做数据分析,首先要有数据来源。以最近热门的关键词… Read the rest 永恒君经常会在东方财富网站上面搜集查询一些行业股票信息,如下图:
… Read the rest有不少朋友问永恒君携程网站的酒店信息怎么抓取,今天这篇文章来分享一下使用
… Read the restPowered by WordPress & Theme by Anders Norén