背景说明
不知道现在新的扫描仪有没有这种高级功能:直接把多次扫描的内容批量一键合成pdf文档。永恒君接触过的大部分普通扫描仪貌似只能简单的把文件挨个扫描成pdf或者图片格式(jpg、png等)。
扫描完成的后续,诸如裁剪、合并、生成pdf等操作,还需要一个个手工完成,非常的费劲。
需求说明
因为的工作的原因,永恒君需要用扫描仪扫描几百页的纸张,然后分类别合并,生成pdf文档。为了好说明,简化如下:

扫描了10张图片(每张图片为A3大小),分两个文件夹分别进行如下操作:
1、每个文件夹的图片要剪裁成A4大小
2、将裁剪的图片合并成pdf。

也就是说,要把1、2两个文件夹里面的扫描件按A4纸张分别合并成2个pdf文档。
思路
都是程序化的操作,非常适合python来进行批量的解决这个问题。
1、关于图片处理,python中有专门的库 - PIL
基本代码如下:
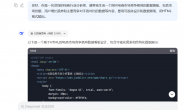
from PIL import Image
img = Image.open(file)#打开图片
img1 = img.transpose(Image.ROTATE_270)#逆时针旋转
cropped = img1.crop((93, 0, 93+1655, 0+2330)) #图片剪裁位置的坐标,依次为左上角坐标和右下角坐标。
cropped.save("1.jpg")#图片保存
2、通过第三库 fitz来合并图片为pdf
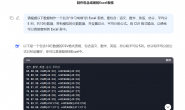
import fitz
def pic2pdf(path):
doc = fitz.open()
for img in sorted(glob.glob(path+"*.jpg")): # 读取图片,确保按文件名排序
print(img)
imgdoc = fitz.open(img) # 打开图片
pdfbytes = imgdoc.convertToPDF() # 使用图片创建单页的 PDF
imgpdf = fitz.open("pdf", pdfbytes)
doc.insertPDF(imgpdf) # 将当前页插入文档
if os.path.exists("allimages.pdf"):
os.remove("allimages.pdf")
doc.save("allimages.pdf") # 保存pdf文件
doc.close()
3、针对所有文件夹,循环进行上述操作即可。
效果

效果:
主要实现了两个批量操作的功能:图片处理、图片转pdf并合并
其实关于图片的其他一些诸如格式、大小、背景、方向,pdf诸如合并、拆分、剪裁等等都可以通过python来实现。
关于文章的素材和python源码,感兴趣的可以回复「扫描处理」获取。
你可能还会想看:
1、教你如何用python制作一个微信机器人陪你聊天,只要几行代码
2、用python定制网页跟踪神器,有信息更新第一时间通知你(附视频演示)
3、把python网页跟踪神器部署到云上,彻底解放你的电脑
4、Python帮你定制批量获取你想要的信息
5、带你看看不一样的微信!
6、微信一键统计、自动通过申请、自动回复(操作演示)
7、python工具分享 - 在线小说一键下载
8、这样获取可转债行情信息,直观又方便
9、Python帮你定制批量获取智联招聘的信息
10、用python给女友准备个礼物吧~
11、python实现浏览器自动化操作
微信公众号:永恒君的百宝箱
个人博客:www.yhjbox.com
转载请注明:永恒君的百宝箱 » 面对大量的扫描文件,你还在挨个手工处理吗?