
 上一篇文件用VBA介绍了如何实现一键按列分类汇总并保存单独文件,代码有几十行,而且一旦数据量多了,效果可能不尽如人意。
上一篇文件用VBA介绍了如何实现一键按列分类汇总并保存单独文件,代码有几十行,而且一旦数据量多了,效果可能不尽如人意。
文章可以参见这里:vba实例(27)-一键按列分类汇总并保存单独文件
今天就来给大家说说如何用python来实现这个效果,先给大家看看效果:
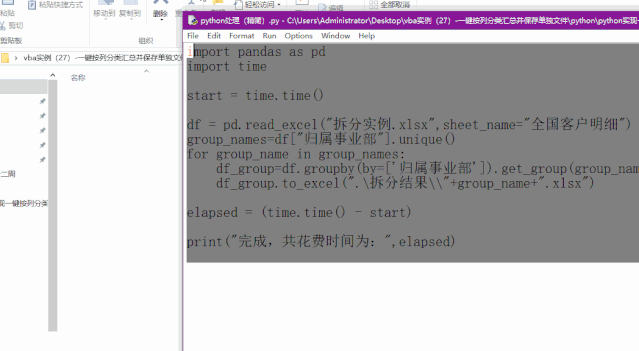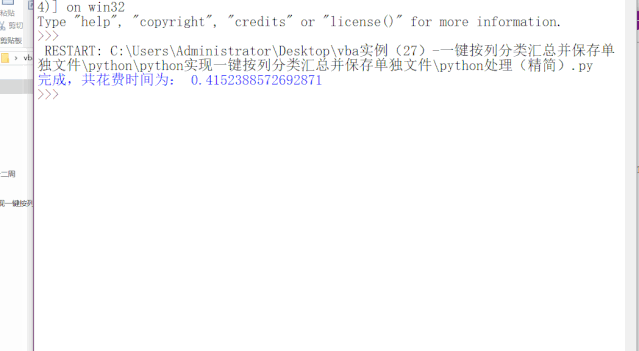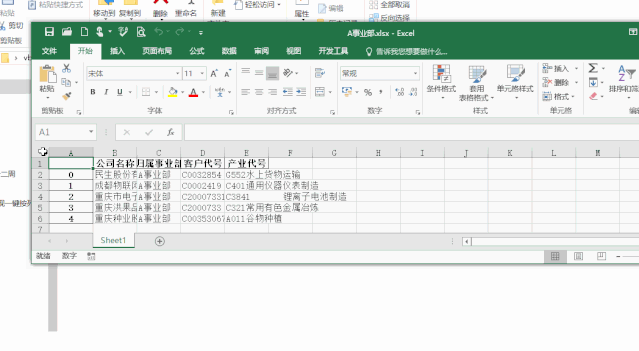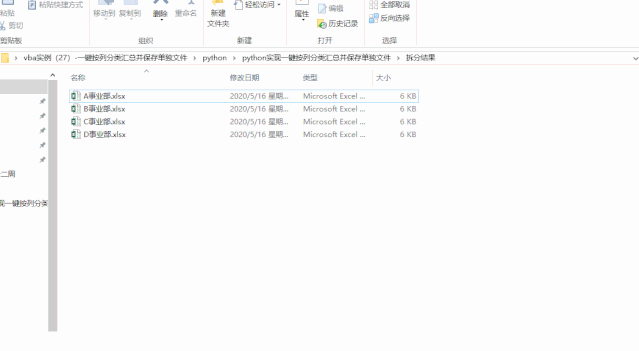
代码只有十几行,效果要提升好多倍,这也是使用python的优势所在。
思路与代码详解
核心思路基本和VBA的一致:读取excel数据 – 获取“归属事业部”列中事业部种类数 – 按每个事业部进行整行提取 – 保存xlsx文件。
1、这里使用的是python中的pandas数据处理库,这个是在数据处理界非常牛逼的一个工具库,使用之前需要导入库。
import pandas as pd
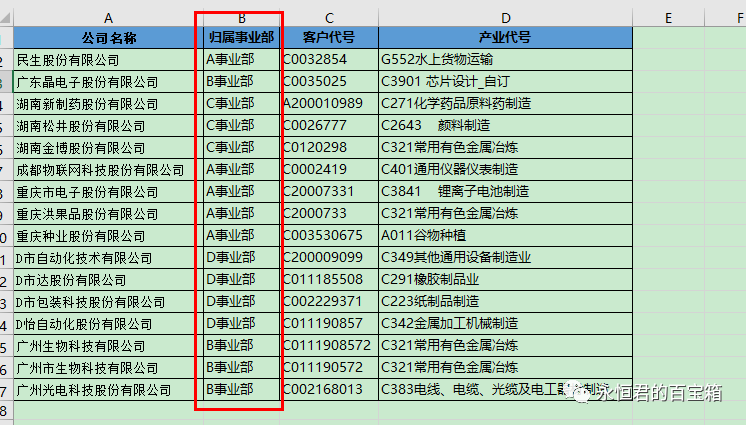
2、读取excel的数据。读取”拆分实例.xlsx”这个excel中,sheet名字为”全国客户明细”的数据,将读取的内容赋值给df。
df = pd.read_excel("拆分实例.xlsx",sheet_name="全国客户明细")
3、获取“归属事业部”列的种类数,使用pandas库的unique方法,将所有事业部的名字赋值给变量group_names。
group_names=df["归属事业部"].unique()
4、将某个事业部的数据整行提取出来保存成xlsx文件,并按事业部的名字进行命名。
df_group=df.groupby(by=['归属事业部']).get_group(group_name).reset_index(drop=True)
df_group.to_excel(".\拆分结果\\"+group_name+".xlsx")
5、遍历每一个事业部,进行同样的操作。
for group_name in group_names:
完整代码如下:
import pandas as pd
import time
start = time.time()
df = pd.read_excel("拆分实例.xlsx",sheet_name="全国客户明细")
group_names=df["归属事业部"].unique()
for group_name in group_names:
df_group=df.groupby(by=['归属事业部']).get_group(group_name).reset_index(drop=True)
df_group.to_excel(".\拆分结果\\"+group_name+".xlsx")
elapsed = (time.time() - start)
print("完成,共花费时间为:",elapsed)
优化
上面这个代码生成的excel,数据是没有任何问题,但是单元格格式比较简陋,甚至可以说“丑”。
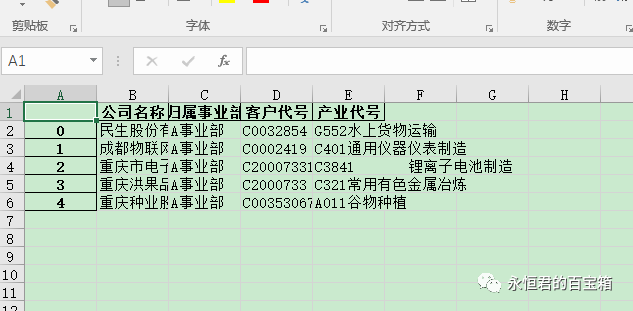
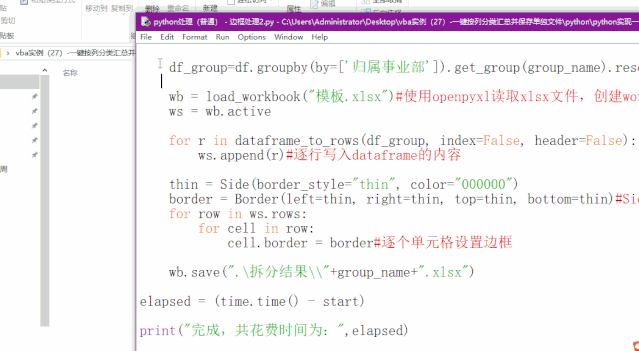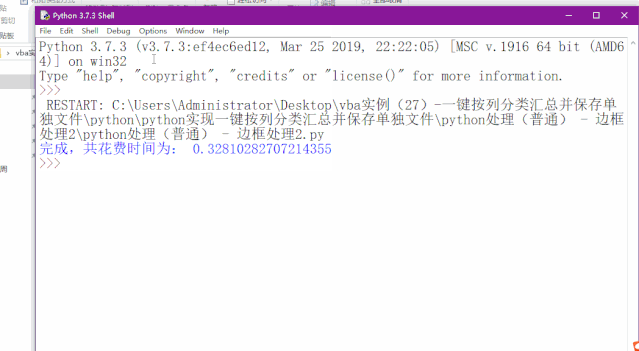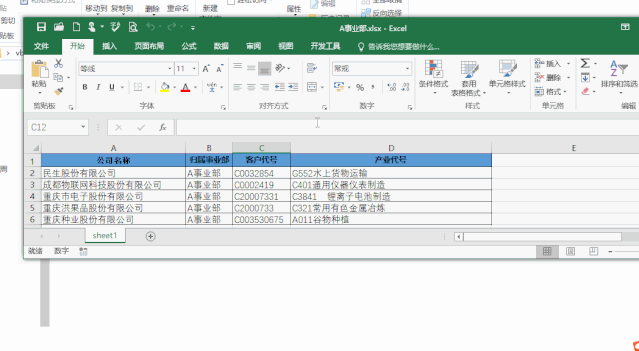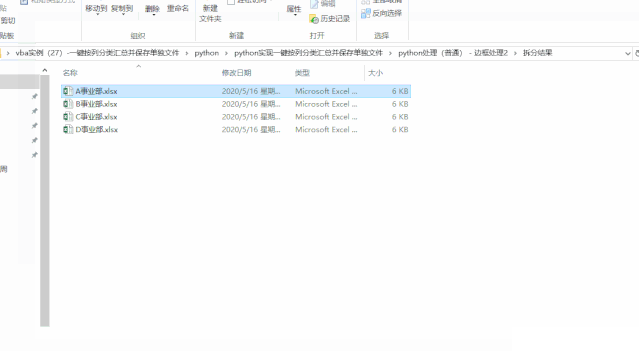
如果需要如下图像生成VBA的比较美观的样式,要怎么弄呢?需要做一些格式上的处理。
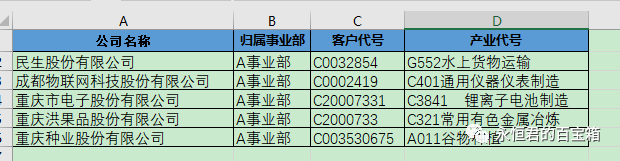
可以新建一个“模板”文件,
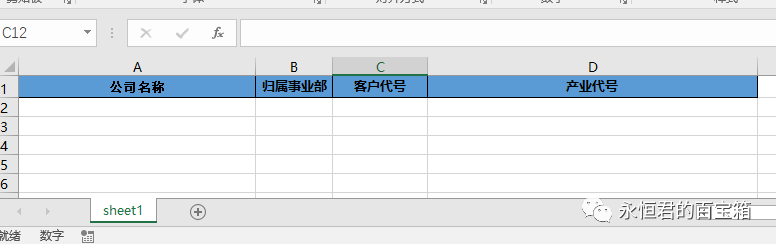
然后调用openpyxl库将分类的数据dataframe写入到模板文件中,设置边框等格式,另存为xlsx文件即可。

效果如下:
微信公众号:永恒君的百宝箱
个人博客:www.yhjbox.com