
web scraper这款chrome插件的一些实例用法。关于web scraper,之前介绍了很多次了。使用它可以方便的仅仅通过鼠标进行简单配置,就可以爬取你所想要数据。例如电影信息、电商网站商品信息、知乎回答列表、微博热门、微博评论等等。文章开始之前需要先安装好web scraper,具体可以参考这篇文章:Web Scraper 使用教程(一)- 安装
话不多说,先上实例。
假设我们需要爬取猫眼电影网站上top100的榜单
(https://maoyan.com/board/4)
爬取这100部电影的排名,电影名称,主演,上映时间,得分。
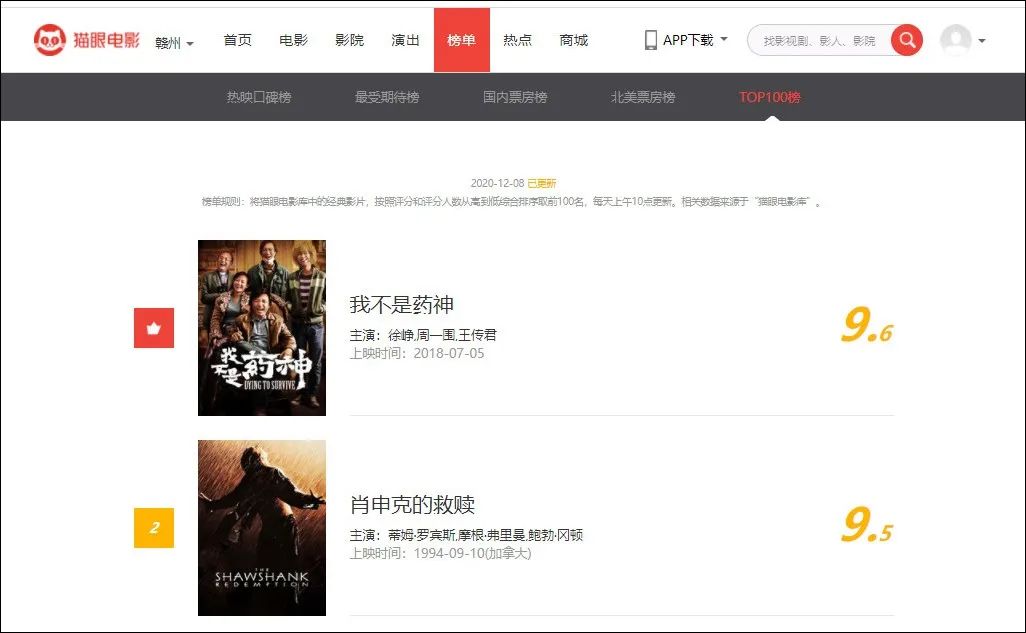

可以看到,这100部电影是分了10个页面进行展示的,每个页面的网址是有规律的,
比如第2页是
https://maoyan.com/board/4?offset=10
第3页是
https://maoyan.com/board/4?offset=20
也就是说,这10个页面的地址是这个样子变化的:
https://maoyan.com/board/4?offset=[0-90:10]
其中[0-90:10]表示每次取值从0到90,间隔10取一次。第1页取0,第2页取10,第3页取30,以此类推。
有了这个地址,我们就可以进行后续的操作了。
1、浏览器里按F12启动web scraper,点击”creat new sitemap”,新建一个项目,名字可以随意起,”start url”填写上面找到的地址,如下图:

2、设置”element”选择器,点击前两部电影后,web scraper会自动将填好代码,点击”done selecting”即可,保存。

3、点击进入刚刚创建的selector,开始配置需要爬取的电影详细内容,方法和第二步是一样的。例如:抓取电影的排名设置,

同样的,电影名称,主演,上映时间,得分依次设置好

至此,所有设置就完成了,看一下总体的结构图:


4、启动插件,运行即可,几秒就就可以搞定了。

爬取的数据可以保存为csv文件,内容如下:

如果你也想体验一下的话,永恒君把整个sitemap文件准备好了点击这里进行查看,或者公号后台直接回复“猫眼电影”即可获取。
这里说一下怎么用,F12启动web scraper后,点击”create new sitemap” – “import sitemap”,然后将txt内容粘贴进去,任意取一个名称,导入即可。
这样就和永恒君电脑上的配置一样了,直接点击运行就可以看到效果了。
2、Web Scraper 使用教程(二)- 基本用法之安装、配置、运行
3、Web Scraper 使用教程(三)- 基本用法(常用选择器类型)
4、Web Scraper 使用教程(四)- 进阶用法(同一个页面爬取多个类型内容)
5、Web Scraper 使用教程(五)- 进阶用法(爬取向下滚动加载页面)
8、Web Scraper 使用教程(八)- 进阶用法(点击「更多」进行翻页)
微信公众号:永恒君的百宝箱
个人博客:www.yhjbox.com