
背景需求
有不少朋友问永恒君携程网站的酒店信息怎么抓取,今天这篇文章来分享一下使用web scraper来快速实现抓取携程酒店信息。
例如,在携程官网搜索北京 密云水库的酒店信息,
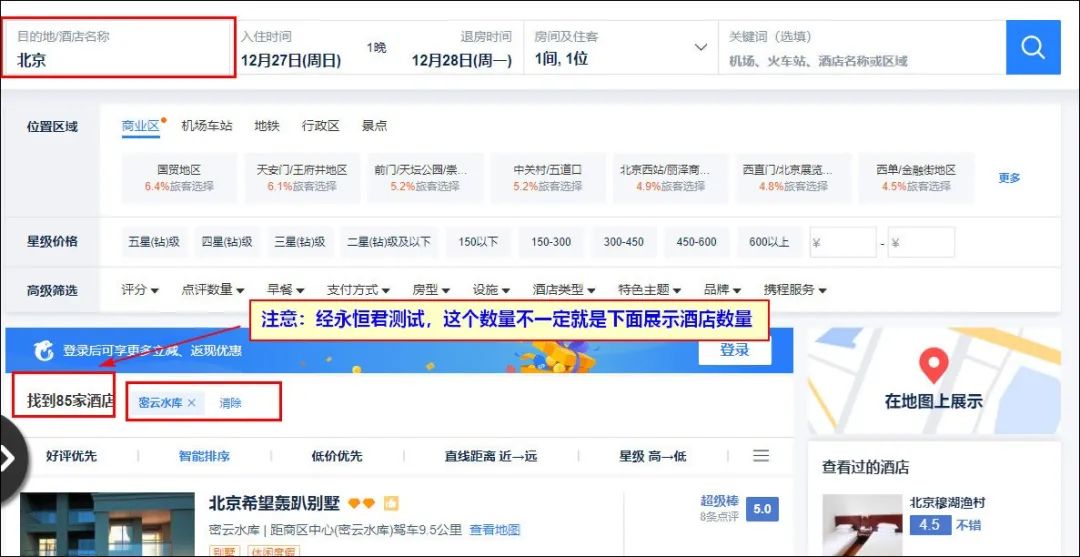
可以搜索到非常多的酒店信息。需要注意的是,搜索出来显示的总数量,经永恒君测试,这个数量不一定就是下面展示酒店数量。
我们需要爬取每个酒店的名称、位置、评分、评价、点评数量、价格信息。
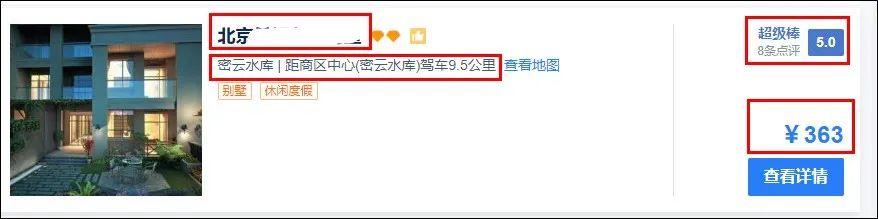
需求分析
通过仔细观察,我们发现:
1、搜索页面不会把所有的酒店信息全部显示出来,需要用鼠标向下滚动页面之后,才会加载后续的酒店信息。
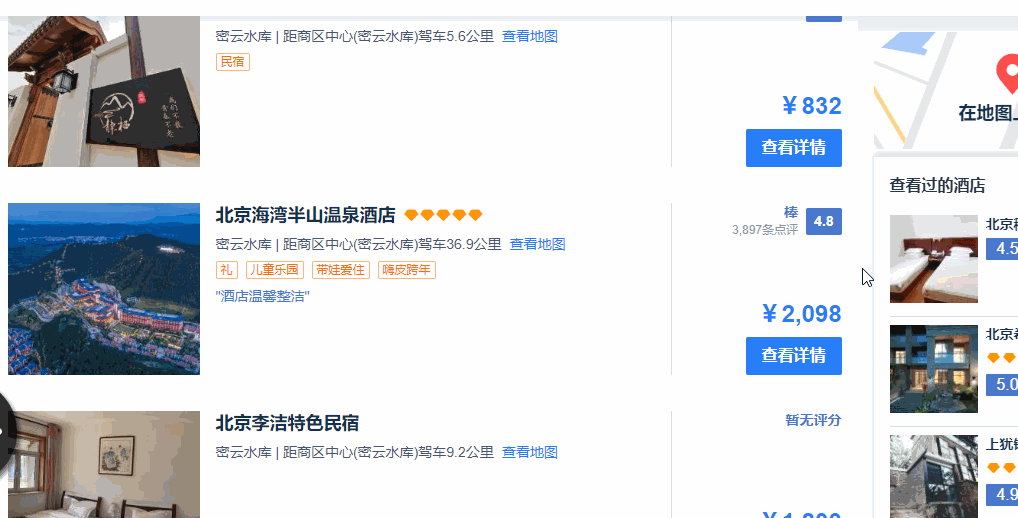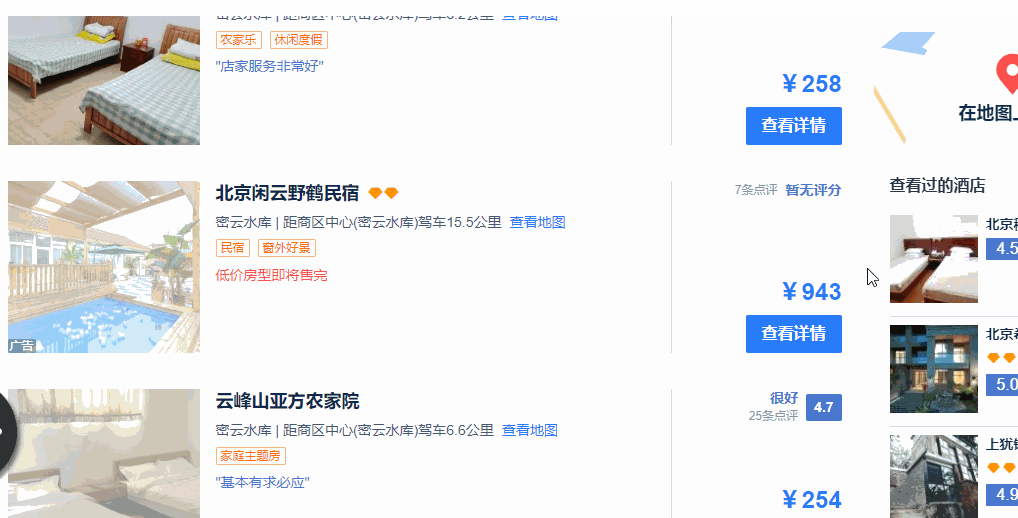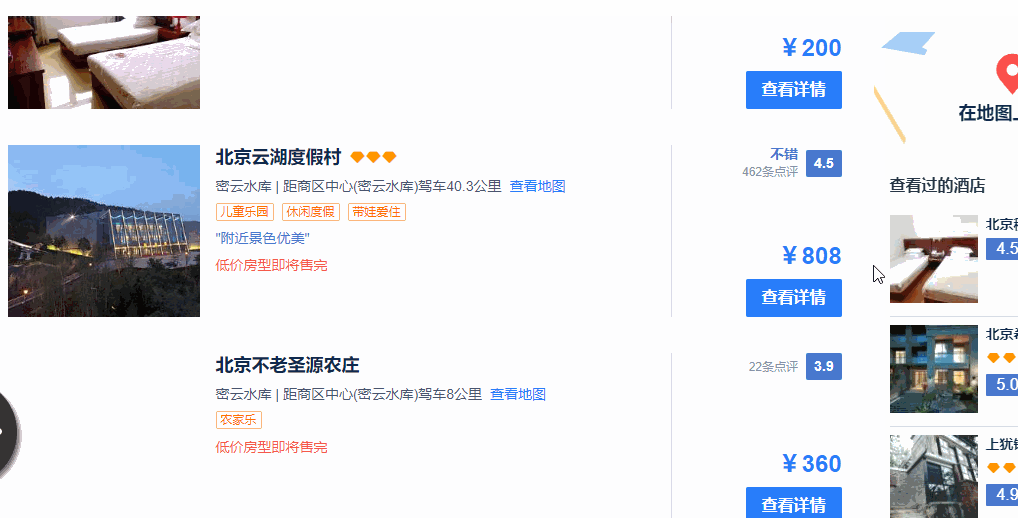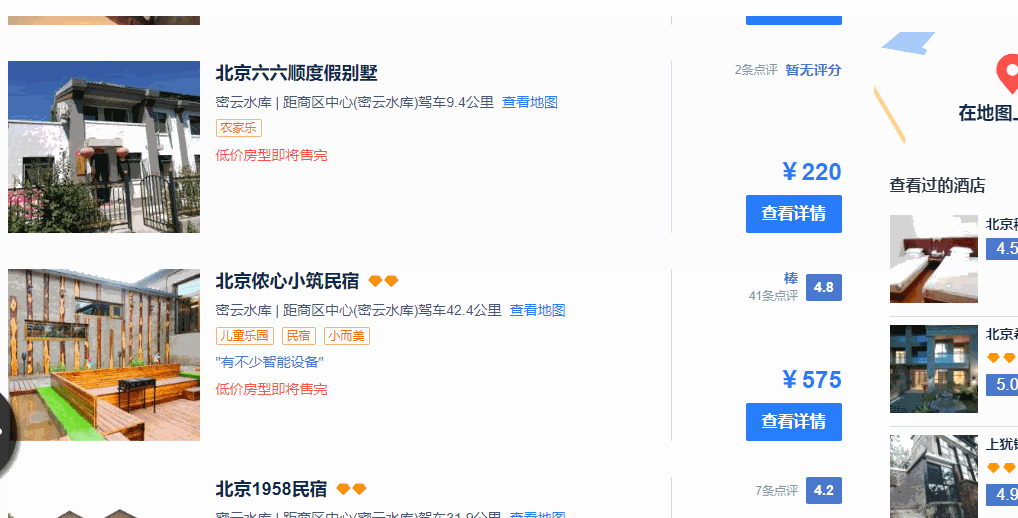
2、滚动了两页之后,就不会自动进行页面的加载了。这个时候需要点击页面上的“搜索更多酒店”,网页才会进一步加载后续酒店的信息,直到“搜索更多酒店”这个按钮消失。
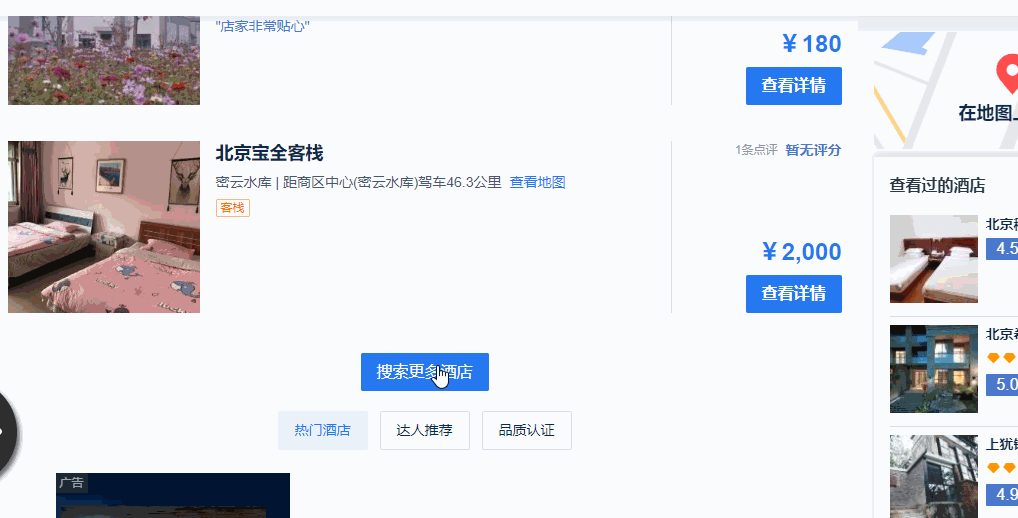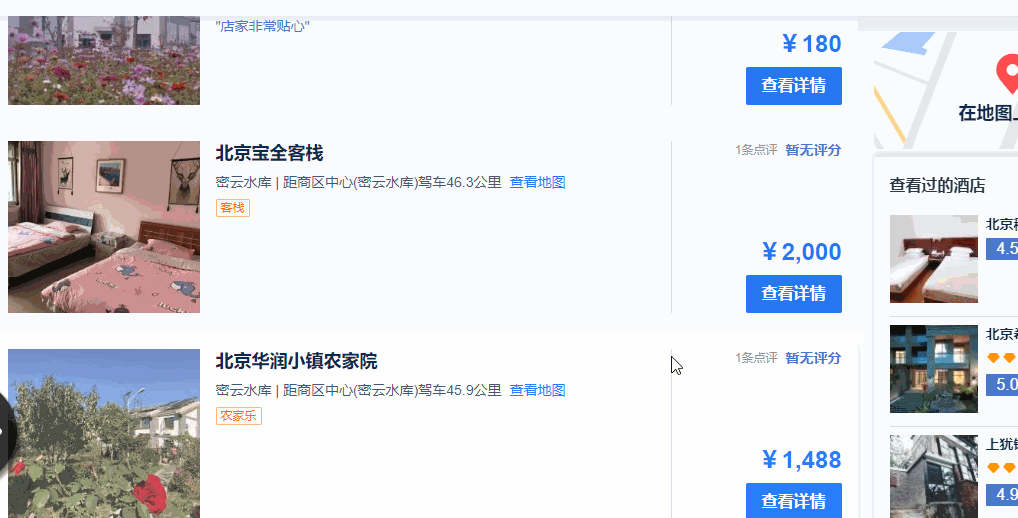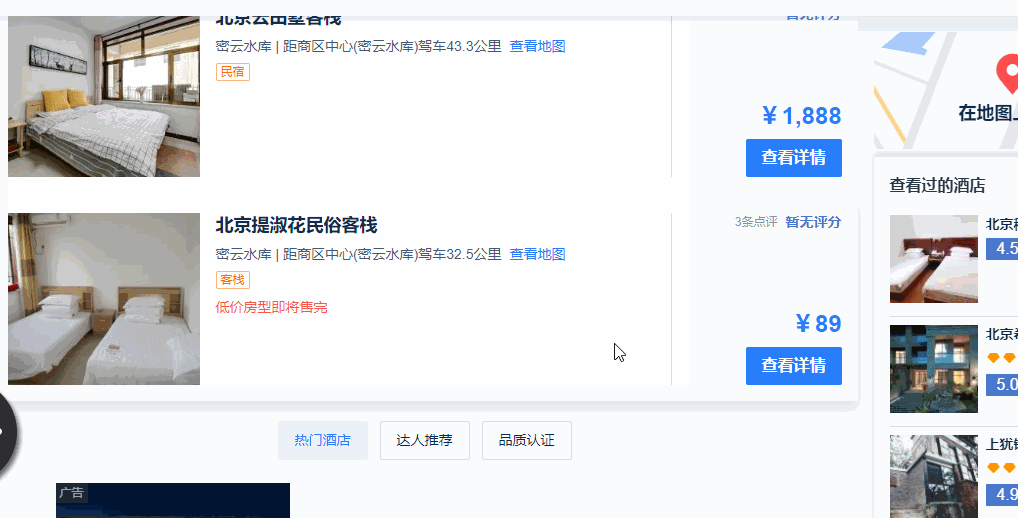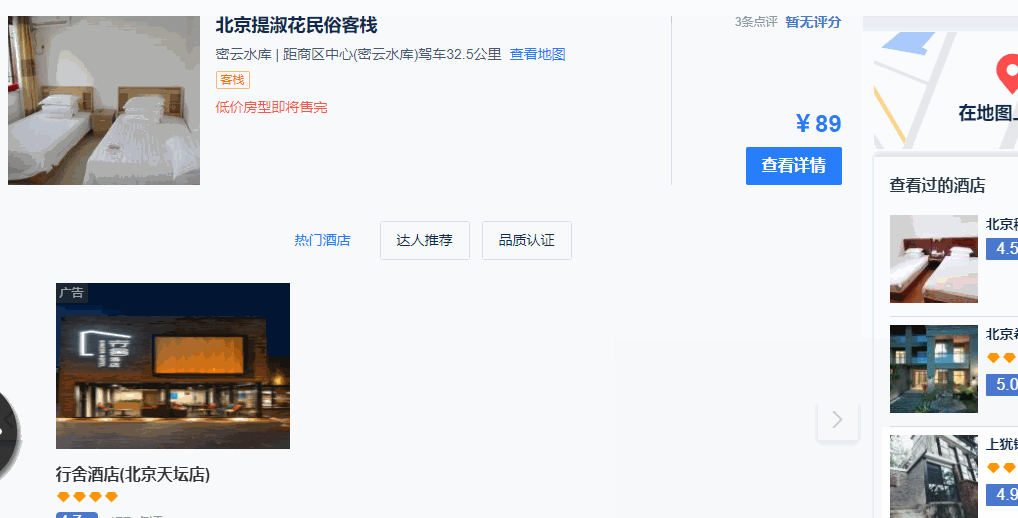
3、当“搜索更多酒店”这个按钮消失之后,所有的酒店信息才展示完全,即才可以抓取到这所有的酒店信息。(故,酒店数量多的时候,需要的时间会比较长,需要耐心等待)
配置运行
通过上面的分析可以知道,要抓取携程酒店的信息,整个过程需要:
1、向下滚动两次加载页面
(参考知识点:爬取向下滚动加载页面)
2、然后再点击多次“搜索更多酒店”按钮
(参考知识点:点击「更多」进行翻页)
将两个操作合并起来,就可以实现酒店信息的爬取了。具体的配置就不详细介绍了,永恒君会将sitemap文件在文后分享。
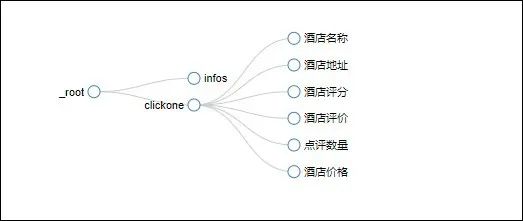
整体的一个结构图就是这样:
爬取的过程演示:
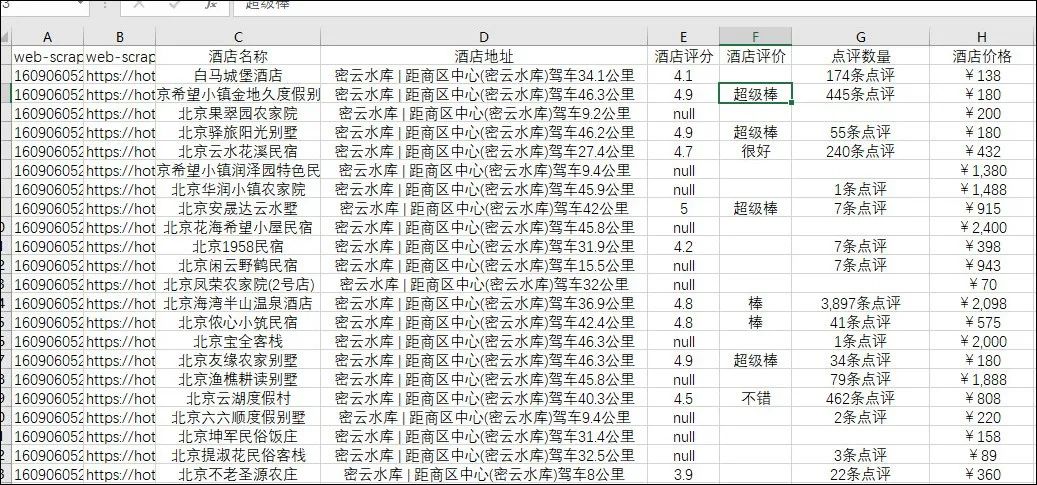
爬取的结果如下:
自定义爬取修改
上面花了这么多时间来进行分析和配置,当然不能只用一次,搜索其他关键词一样是可以使用的,只不过需要做一点点适当的修改。
假如这个时候,需要抓取另外一个地方的酒店信息,比如说青岛流亭机场 600元以上的酒店信息,应该怎么操作呢?
同样的,在携程官网搜索青岛的酒店,然后选择流亭机场 600元以上这些条件,
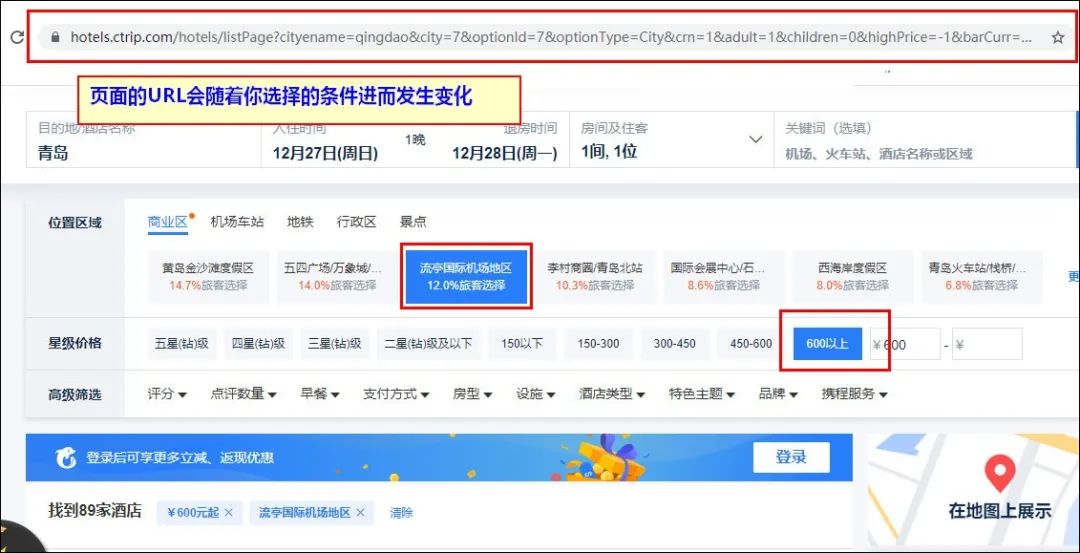
这时候你会发现,页面的URL会随着你选择的条件发生变化,我们需要把这个URL复制下来,做如下的修改:
删除掉:
&checkin=2020/12/27&checkout=2020/12/28
以及#ctm_ref=ctr_hp_sb_lst这两部分内容。
例如:浏览器URL地址为
https://hotels.ctrip.com/hotels/listPage?cityename=qingdao&city=7&checkin=2020/12/27&checkout=2020/12/28&optionId=7&optionType=City&crn=1&adult=1&children=0#ctm_ref=ctr_hp_sb_lst&highPrice=-1&barCurr=CNY&zone=4123&sort=9&lowPrice=600&priceQuickFilters=5
(加粗的位置需要删除)
那么修改后为
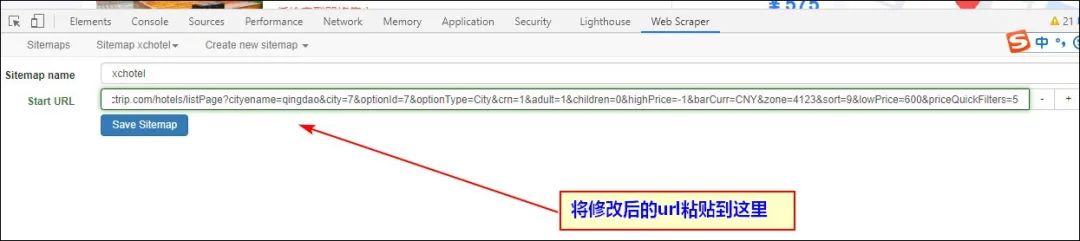
https://hotels.ctrip.com/hotels/listPage?cityename=qingdao&city=7&optionId=7&optionType=City&crn=1&adult=1&children=0&highPrice=-1&barCurr=CNY&zone=4123&sort=9&lowPrice=600&priceQuickFilters=5
将修改后的地址复制到web scraper的起始URL当中,其他的不用做修改,然后运行即可。
爬取的结果如下:
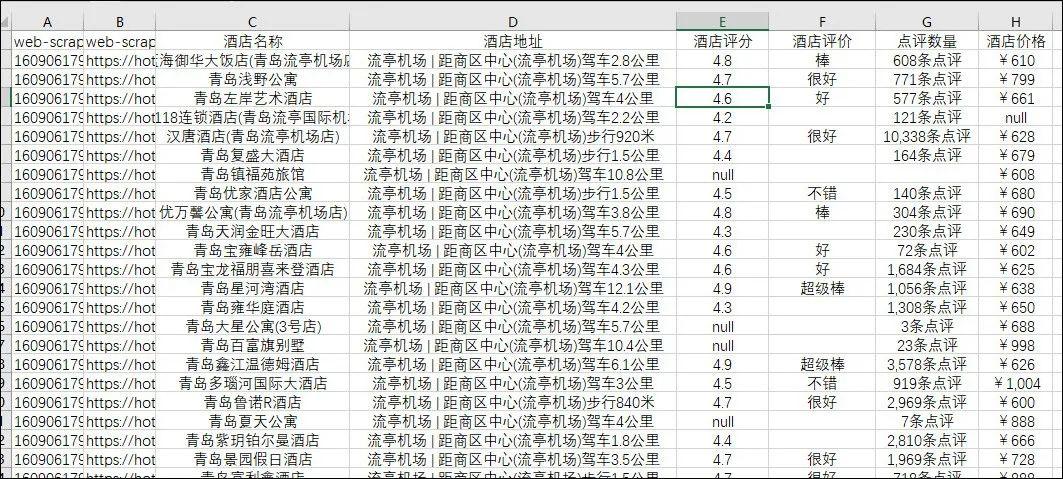
通过这样修改URL的方法,你可以想搜什么,就抓取什么了。

永恒君把整个sitemap文件放在了公号后台,如果你感兴趣的话,回复“携程酒店”即可获取。
微信公众号:永恒君的百宝箱
个人博客:www.yhjbox.com