
 做数据分析,首先要有数据来源。以最近热门的关键词
做数据分析,首先要有数据来源。以最近热门的关键词比特币为例,今天这篇文章来分享一下,使用web scraper来快速抓取微博热门事件关键词比特币的数据。视频教程:
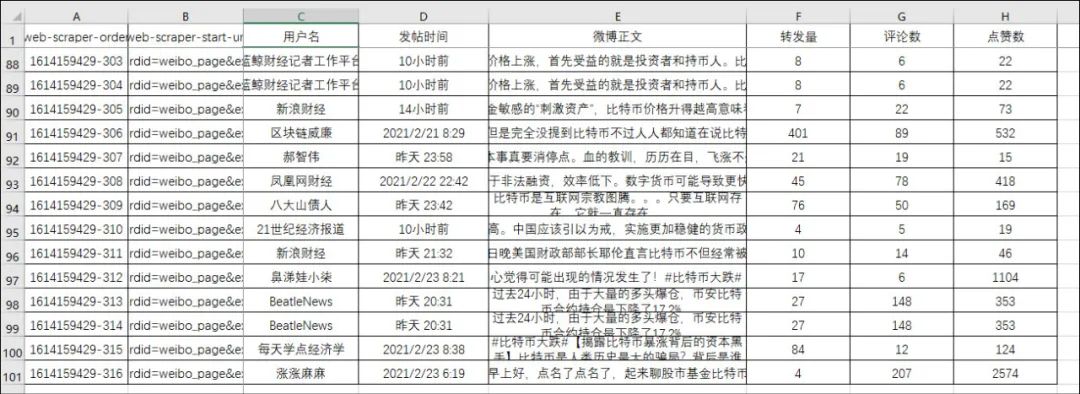
使用的是微博移动端https://m.weibo.cn/,想要爬取的对象有用户名、正文、时间、转发数、点赞数、还有评论数。
需求分析
页面地址:
https://m.weibo.cn/p/index?containerid=100103type%3D60%26q%3D%E6%AF%94%E7%89%B9%E5%B8%81%26t%3D0
这个页面一直向下拖动,会一直有页面加载出来。永恒君尝试了好久都拉不到底,那应该是可以无限的向下提取内容的。
这样的话,我们需要限定一下抓取的内容数量,否则程序就一直会滚动下去,那么数据也就等于抓不到了。比如说我们就抓取前100条微博信息。
这个实例需要用到的选择器是之前介绍过的Element scroll down(传送门)
配置运行
1、Element scroll down选择器配置
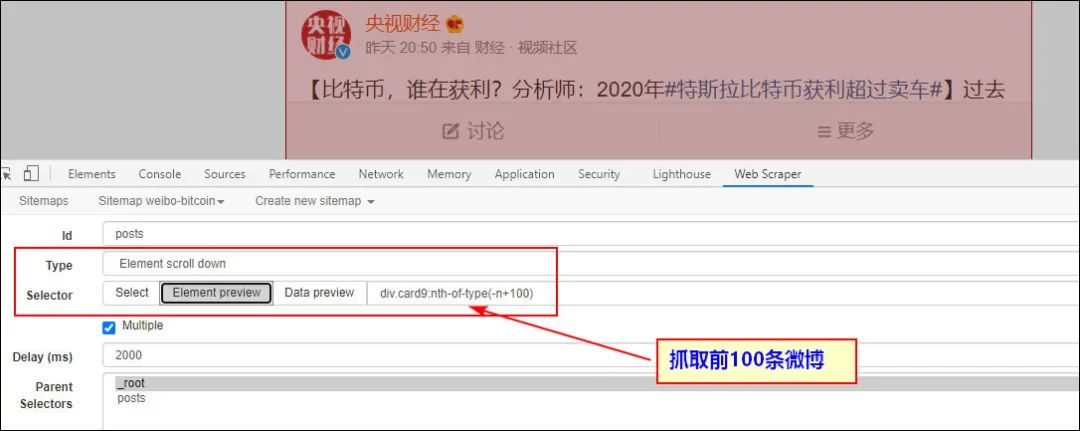
注意:抓取前100条微博信息selector需要在页面选择好元素后,手工输入:nth-of-type(-n+100),类似的如果你想抓取100到200页,那么就输入:nth-of-type(n+100):nth-of-type(-n+200)
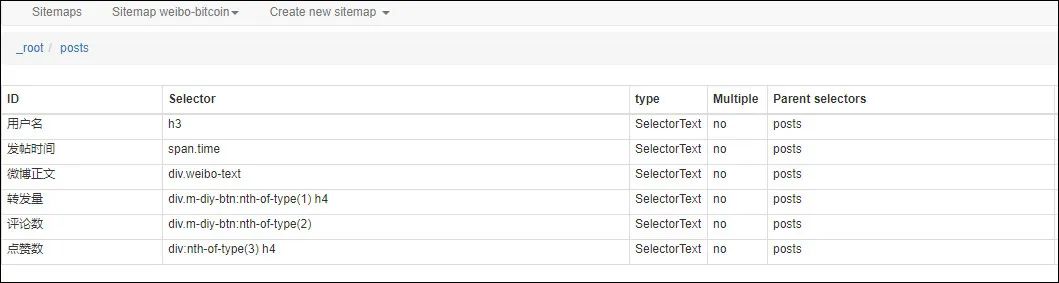
2、接下来配置抓取用户名、正文、时间、转发数、点赞数、评论数,这个比较简单。

整体的结构图:
web scraper爬取的结果:
更换关键词
如果要更换爬取的关键词,比如“基金”,按下面的方法把web scraper的爬取起始页更改一下即可。
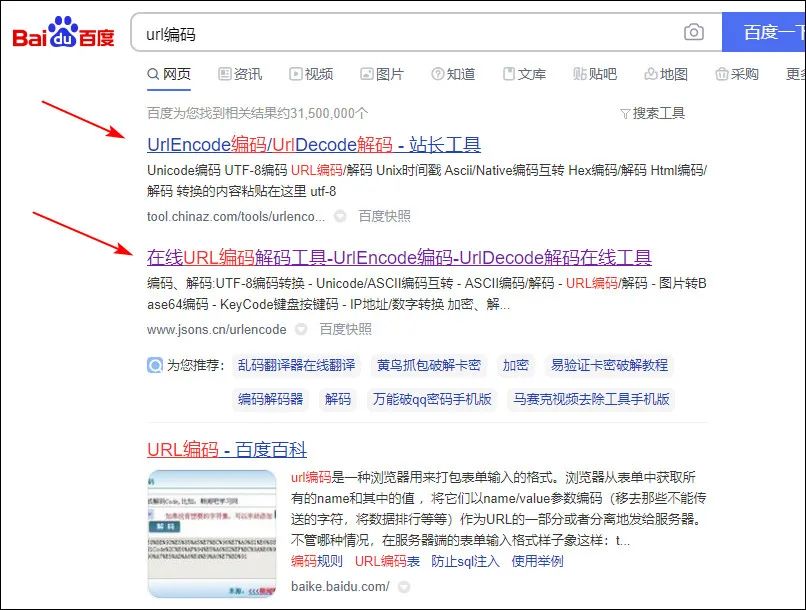
1、百度里面搜索“url编码”,随意打开一个在线的编码工具。
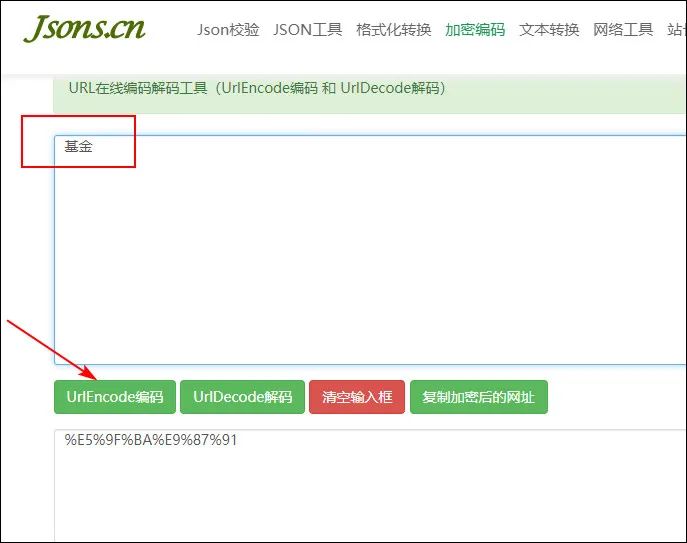
2、输入“基金”,点击“UrlEncode编码”,下面会生成一段编码。
3、回到上面爬取“比特币”的微博地址,
https://m.weibo.cn/p/index?containerid=100103type%3D60%26q%3D%E6%AF%94%E7%89%B9%E5%B8%81%26t%3D0
修改一下:
https://m.weibo.cn/p/index?containerid=100103type%3D60%26q%3D%E5%9F%BA%E9%87%91%26t%3D0

将刚刚生成的编码,替换掉上面橙色的代码,这个就是关键词“基金”的爬取起始页面。
之前还写过这些实例:
微信公众号:永恒君的百宝箱
个人博客:www.yhjbox.com