
webscraper就可以帮我们快速的建立这样的目录。
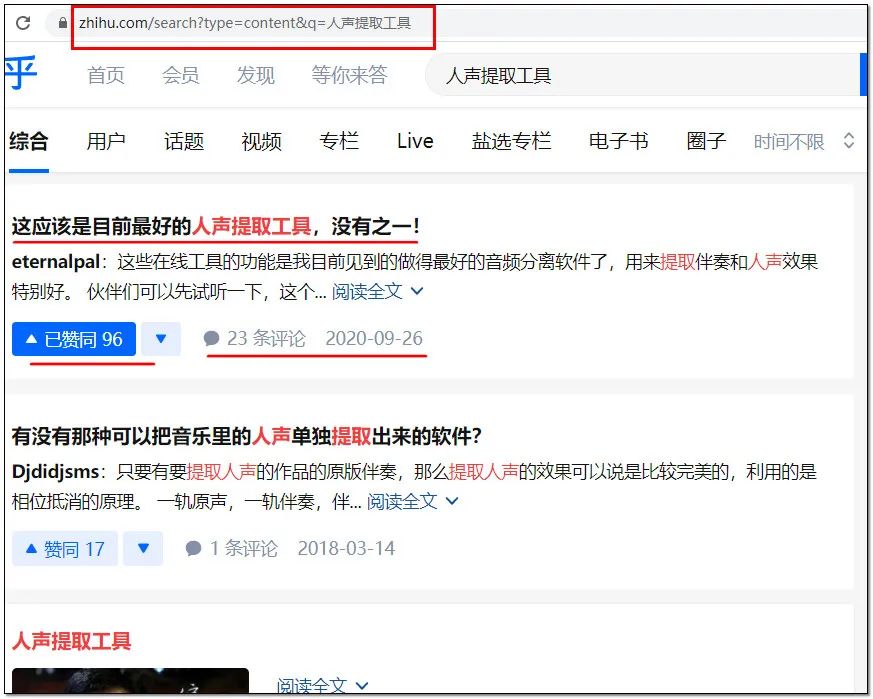
例如,知乎中搜索关键词“人声提取工具”,爬取的前100个文章或者问题的标题、链接、赞同数、评论数、发布日期。
需求分析
页面地址:
https://www.zhihu.com/search?type=content&q=人声提取工具
这个页面一直向下拖动,会有页面加载出来,有的时候可以向下滚动非常多次。为了说明问题,这里只抓取前100个文章或者回答的数据。
这个实例和上一篇爬取热门微博的实例(5)用到的是同一个选择器 – Element scroll down
配置运行
1、Element scroll down选择器配置
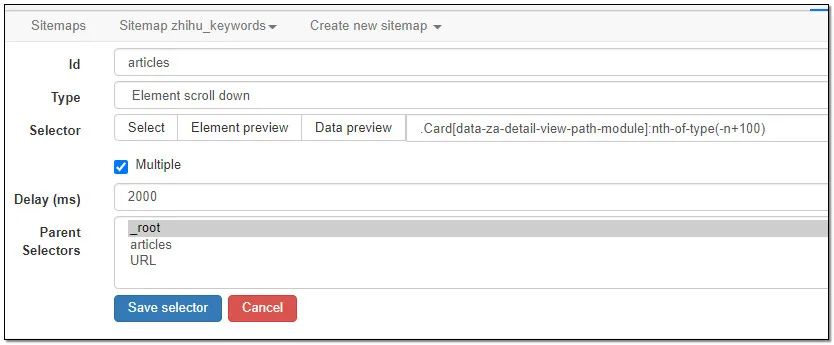
注意:抓取前100条信息selector需要在页面选择好元素后,手工后面输入:nth-of-type(-n+100),永恒君这里添加后的代码是.Card[data-za-detail-view-path-module]:nth-of-type(-n+100)
2、接下来配置抓取标题、链接、赞同数、评论数、发布日期,这个比较简单。

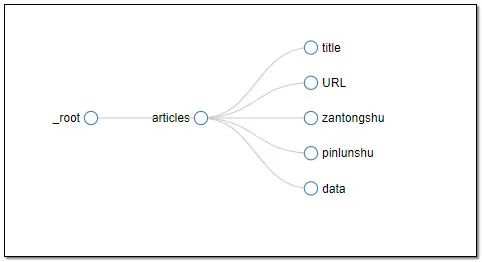
整体的结构图:
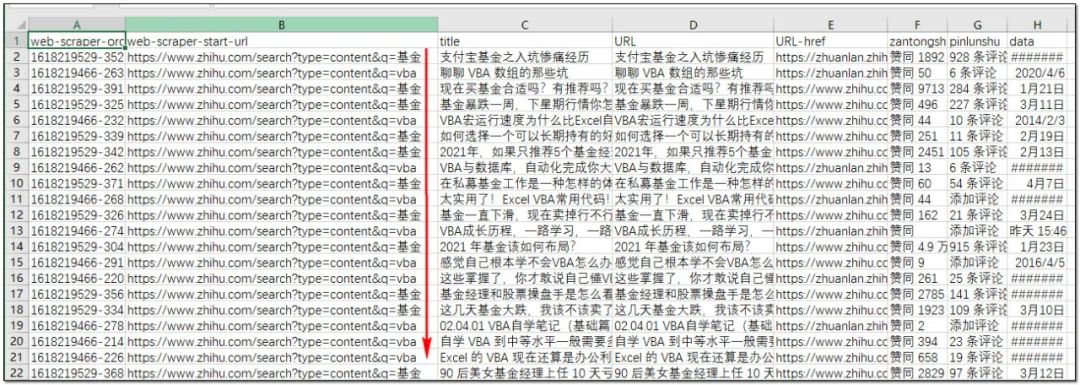
web scraper爬取后稍微整理的结果:
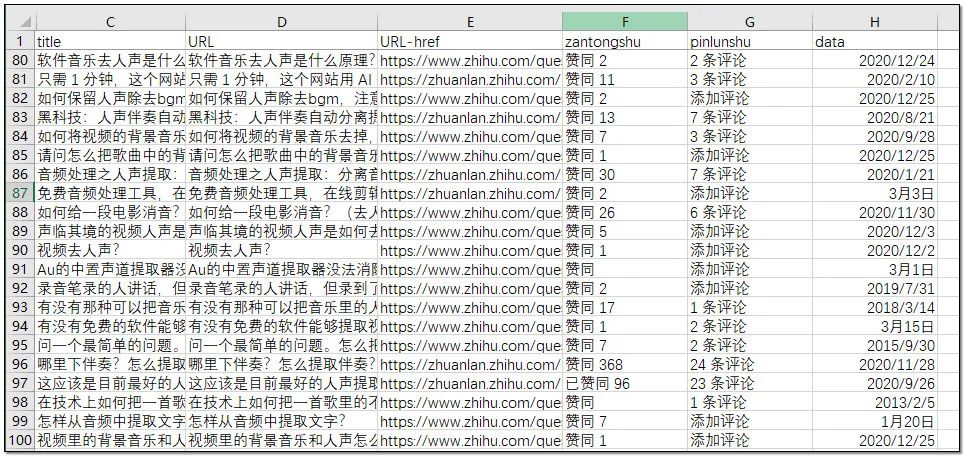
有了这个表格,筛选出高质量文章,或者是一些回答数相对少的问答的很方便了。
更换关键词
如果要更换爬取的关键词,把关键词直接更换一下,输入浏览器即可,比如关键词是“基金”,那么起始网址就是:
https://www.zhihu.com/search?type=content&q=基金
这样的话就可直接使用了。
如果你希望可以同时爬取多个关键词,例如你想一次性爬取“vba”、“基金”两个关键词的搜索。可以在起始页的位置,点击+,挨个添加即可。

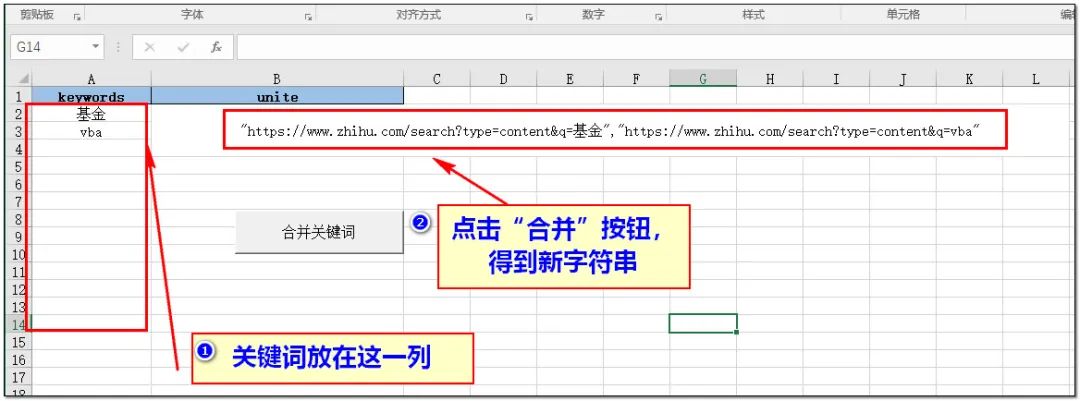
如果你的关键词比较多,需要用到一点小技巧:
1、将所有的关键词复制粘贴到到永恒君写好的excel中第一列,点击“合并”按钮,生成新的字符串序列。
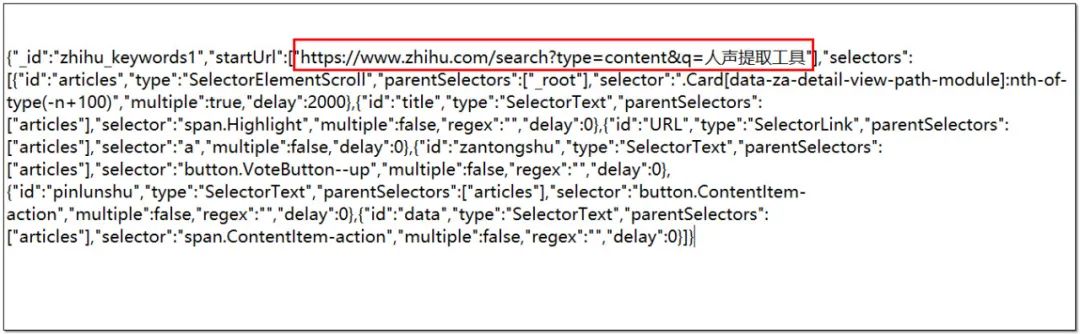
2、打开sitemap,将startUrl后面中括号里面的内容替换成刚刚生成的字符串序列。

3、把这个新的sitemap导入到webscraper当中,保存好。查看起始页的位置,如下图:
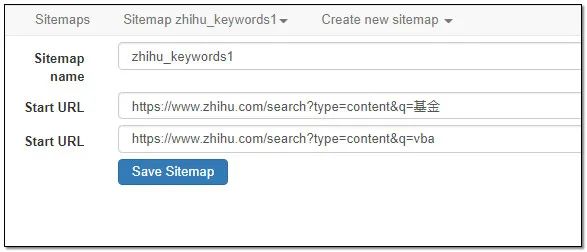
这样说明设置成功了,可以直接运行了。
抓取的结果:
如果你感兴趣的话,永恒君把整个sitemap文件、excel文件打包放在了公号后台,后台回复“zhihu”,尽快获取~~