
如果要备份某个公众号的所有文章,这个就要费点功夫了。网上搜索了一下,免费付费的工具都有,评论效果也是不一而论,不好说。
其实原理比较说起来还是不难的,今天永恒君就来分享一下备份某个公众号的所有文章的思路方法。
以我自己的公众号永恒君的百宝箱为例了,原理是大致是这样的:
- 抓包抓取微信客户端的接口
- 使用Python请求微信接口获取公众号文章链接并下载
1、抓包抓取微信客户端的接口
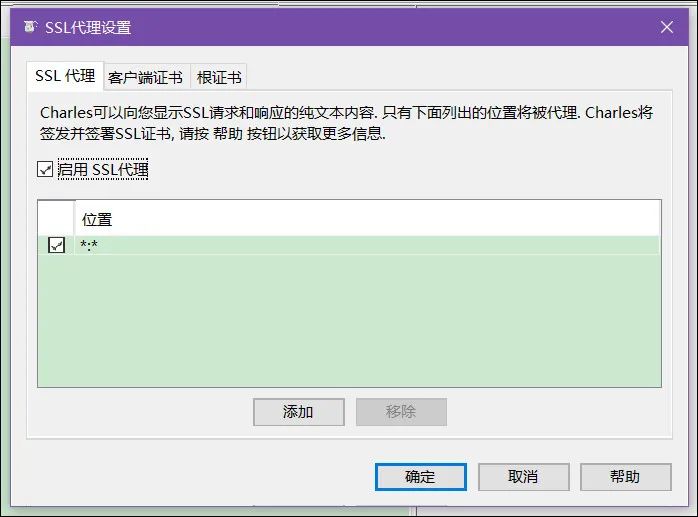
常见的抓包工具有Fiddler,charles等等,永恒君这里用的是charles。
使用之前需要先进行一系列的配置,安装证书,添加域名和host。否则获取不到https接口数据,显示unknown。详细的配置方法可参考这里。
配置好后启动,打开微信客户端找到公众号,进入文章列表可以看到发过的文章。
这样可以抓取到公众号文章接口数据了。
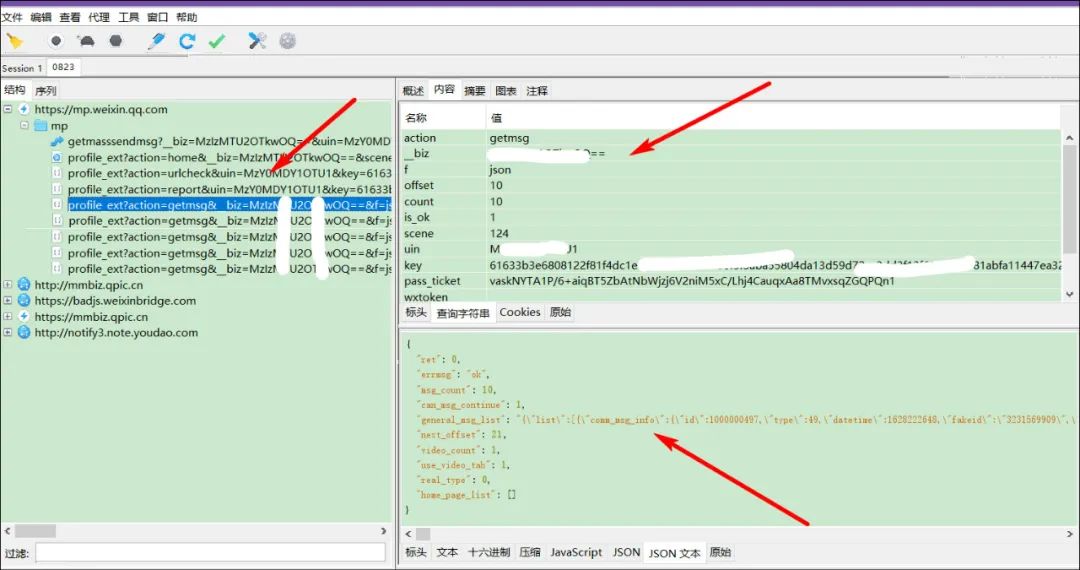
公众号文章的接口地址如下:
/mp/profile_ext?action=getmsg&__biz=MzIzMTU2OTkwOQ==&f=json&offset=10&count=10&is_ok=1&scene=124&uin=MzY0MDY1OTU1&key=61633b3e6808122f2a8e656cab84fa561b091de04bff962f725a959bf7d4e91507cf2f369f5dd89c9346abc8a415882fc2a13b51777dc54fba05e79c2346af8c872d619e7b10b27d515745b96d3ddd0f5fb09083f3bba38b8814be5cd32ab159d4964f299b988d29e1fbbe15ae2aa9f3a572392a143c354ba86df0d29414a0ee
参数比较多,其中有用的参数为:
__biz 是用户和公众号之间的唯一id
uin是用户的id,这个是不变的
key 是请求的秘钥,一段时间就会失效
offset 是偏移量
count 是每次请求的条数
通过上面的请求,就可以获取公众号文章的信息了,包括文章标题titile、文章地址content_url、阅读原文地址source_url、封面cover、作者author,抓取这些就行了。
2、使用Python请求微信接口获取公众号文章链接并下载
有了上面的接口参数,就可以开始用Python请求获取文章信息了。

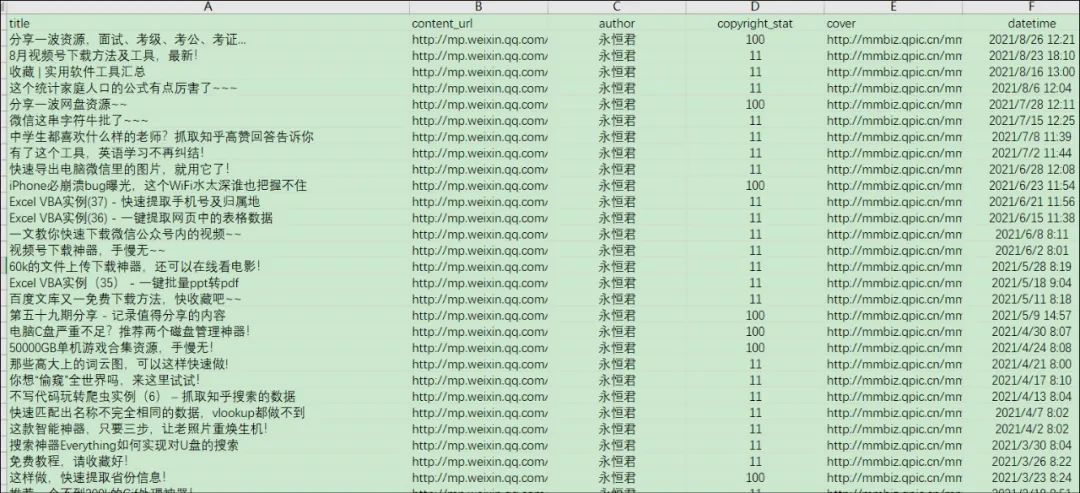
这里只抓取永恒君署名的原创文章,公众号一共有大约230多篇原创,生成HTML文件3分钟就全部下载下来了。
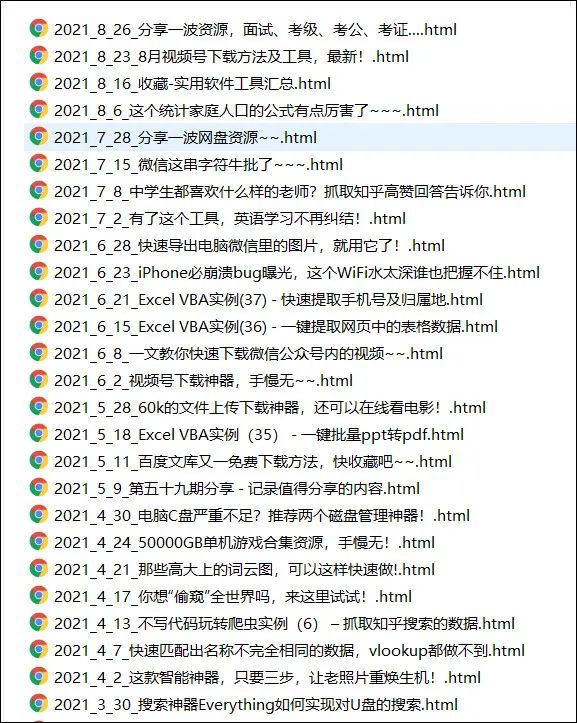
用浏览器打开就能看。
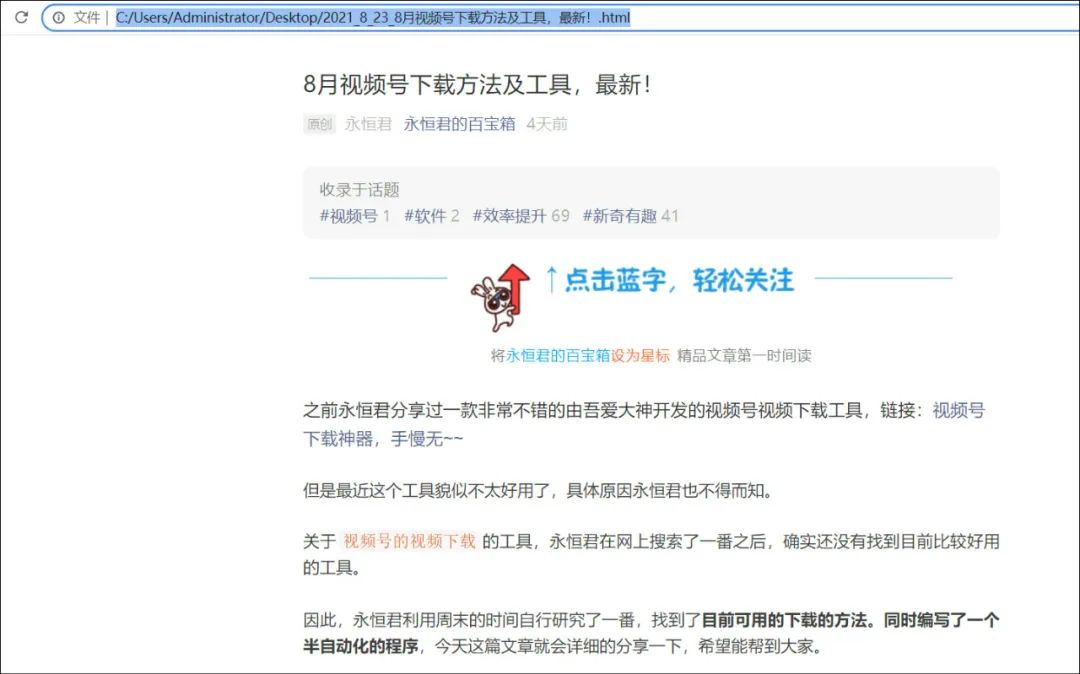
但是有个问题,html文件里面的图片需要联网才能进行查看
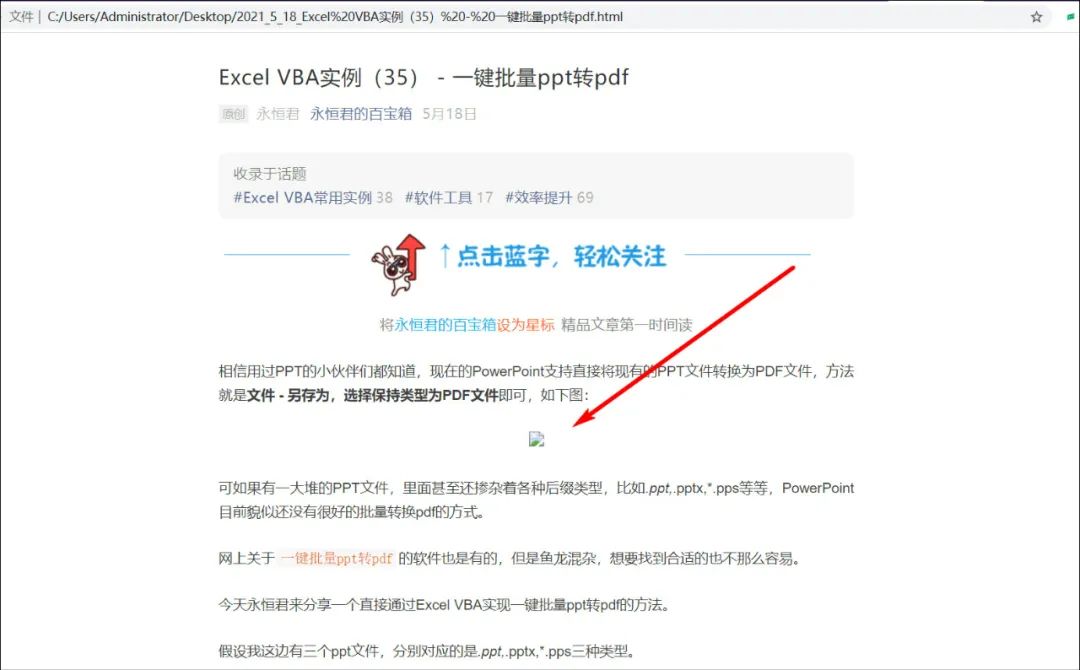
所以永恒君把html文章再用python导出成PDF文档。
导出PDF用的工具是wkhtmltopdf,这里特别说一下,这个工具需要先下载安装 wkhtmltopdf。
接着Python中安装pdfkit库,调用wkhtmltopdf就可以了。
因为需要联网获取图片,因此生成PDF会比较慢,耐心等待几十分钟之后,PDF文件也全部生成了。
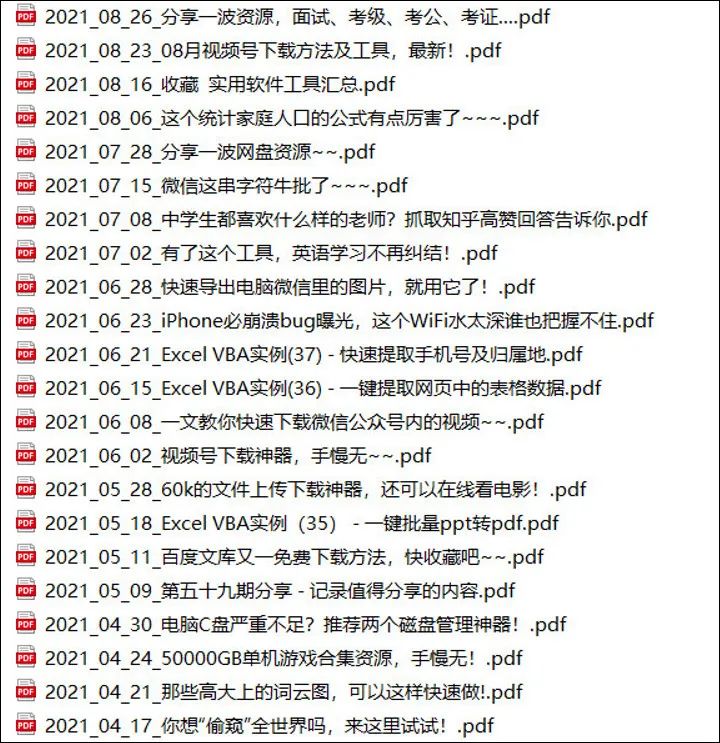
PDF也可以用浏览器直接打开,比如这篇 这个统计家庭人口的公式有点厉害了~~~

如果觉得PDF文件数量太多了,也可以借助pdf合并软件,将所有的pdf合并成单独的合集,目录就以每个文件名命名,方便查找。
这样就完美的把我公众号的所有文章下载到本地了,有HTML和PDF格式。

以上获取文章的代码写的很简陋,还没有做优化,不太方便分享出来,怕误导大家。有需要的话可以联系我帮忙下载公众号文章。
如果你感兴趣,可以在公众号后台回复“合集”获取本公号目前所有PDF原创文章合集。