
新浪微博评论的数据一直是不少做数据分析朋友感兴趣的内容之一,但是获取数据本身可能就难到了不少人。
其实这个用之前介绍的web scraper可以非常容易的实现一个简单、快速的抓取功能,今天永恒君就来分享一下这个过程。
这里抓取的是网页版的新浪微博评论,开始之前必须要有微博账号,要先登录!
需求分析
假设需要提取的微博页面地址是:
https://weibo.com/1402551940/KzMMhg0Ev?filter=hot&page_source=hot&root_comment_id=0&type=comment
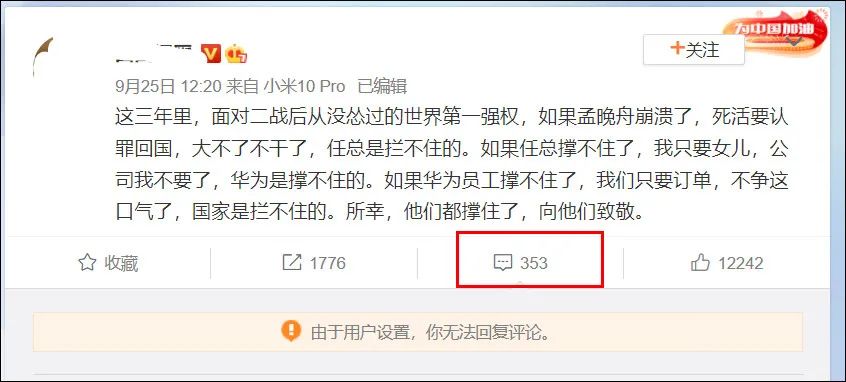
一共有320条评论(不确定这320条是否包含评论的评论)
观察微博这个页面,不难发现,这个页面需要向下拖动几次,才会有新的评论加载出来,之后就需要点击查看更多才会进一步加载评论,如果评论数量多的话,加载的时间会非常的长。
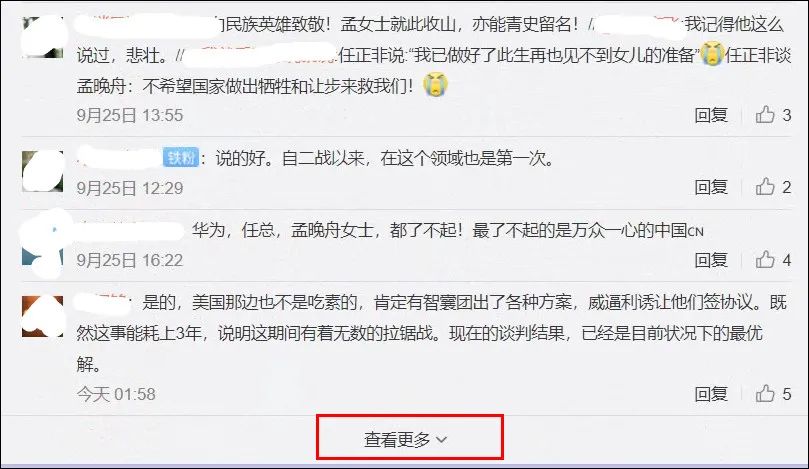
这里很显然主要用到的选择器有两个:Element scroll down 和 Element click
为了说明问题,这里演示只抓取前90个评论的数据。
配置运行
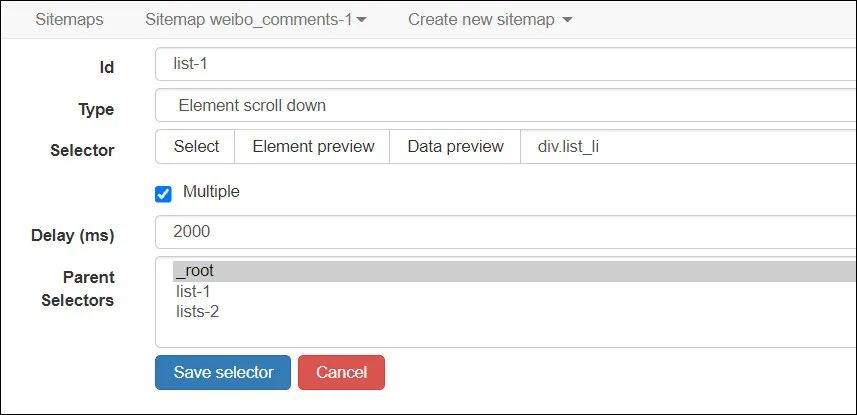
1、Element scroll down选择器配置如下,用来实现向下拖动。
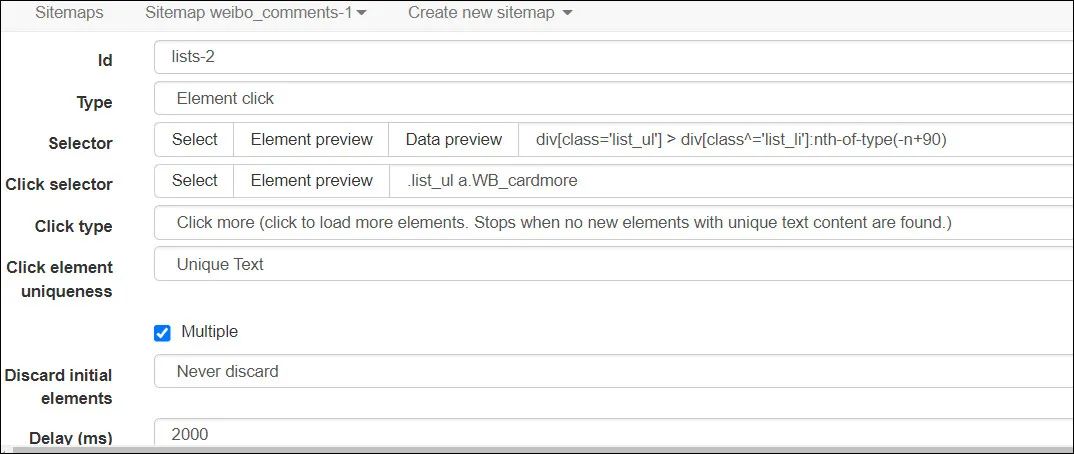
2、Element click选择器配置如下,用来实现点击“查看更多”,加载后面的评论。
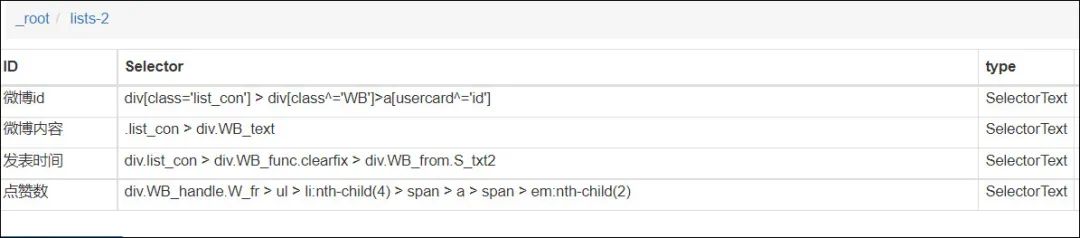
3、剩下的就是配置抓取评论的哪些具体内容,这里只抓取了ID、内容、评论时间、点赞数,如下图:
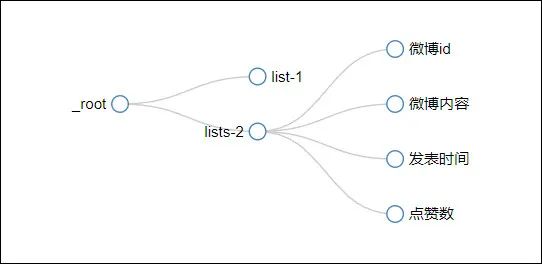
整体的结构图如下:
设置好之后,就可以直接运行了。
抓取的结果:

这里抓取的有些是null的记录,应该是抓取了一些评论的评论内容,筛选删除掉即可,不影响爬取的整体数据。
如果你感兴趣的话,永恒君把整个sitemap文件准备好了,直接点击这里进行查看,或者公号后台回复「评论」获取~~
关于sitemap的使用,参考这里:
不用代码玩转爬虫实例(1) – 抓取猫眼电影信息
关于爬取其他微博的评论数据,参考这里:
不写代码玩转爬虫实例(4) – 抓取东方财富股票信息
关于爬取多个微博的评论数据,参考这里:
不写代码玩转爬虫实例(6) – 抓取知乎搜索的数据