大家好,我是爱分享的永恒君!
最新因为数据分析的原因,需要采集一些关键词在百度的搜索结果。
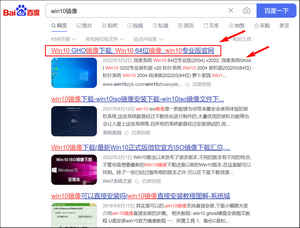
如下图,比方说我要提取搜索结果的标题、URL地址、摘要等一系列的信息。

这个需求还是比较简单的,用web scraper就可以很快实现。
基本思路
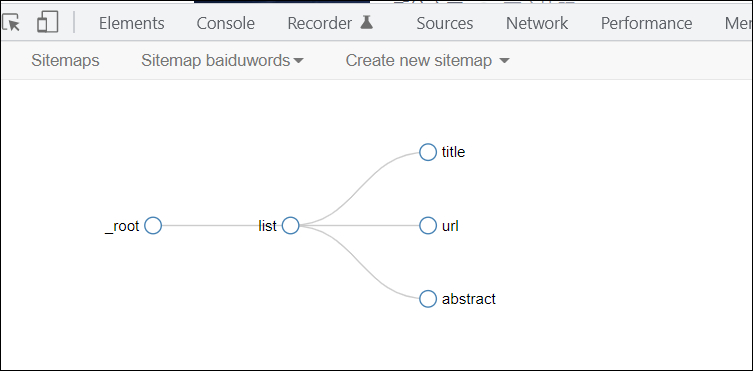
通过新建一个Element的选择器,然后将标题、URL地址、摘要统一放在这个选择器下面即可,整体框架如下:
搜索关键词的首页地址样式大致为:
https://www.baidu.com/s?wd=win10镜像&pn=0&tn=baiduhome_pg&ie=utf-8&usm=1&rsv_idx=2&rsv_pq=d11de23000058900&rsv_t=ad96aKtZzkuHc08DLrkxF2Pmwc%2F8D%2FwY7Wja%2F2H8BYlMku7tP%2FOkMx4TbDsuh34ZeBG5
wd代表搜索的关键词"win10镜像",pn代码的翻页的变量
起始页根据这两个变量自定义设置好即可。
注意问题
不过这里有个问题需要注意,如下图:

直接选择搜索结果里面的标题的话,提取到的url为百度搜索的结果(图中1标示的位置),而我需要的目标网站的网址其实不是这个(是图中2标示的位置)
虽然访问这个结果最终还是会转向目标网站,但还是会不方便,所以注意可以使用Element Attribute来提取真实的目标url即可。
效果
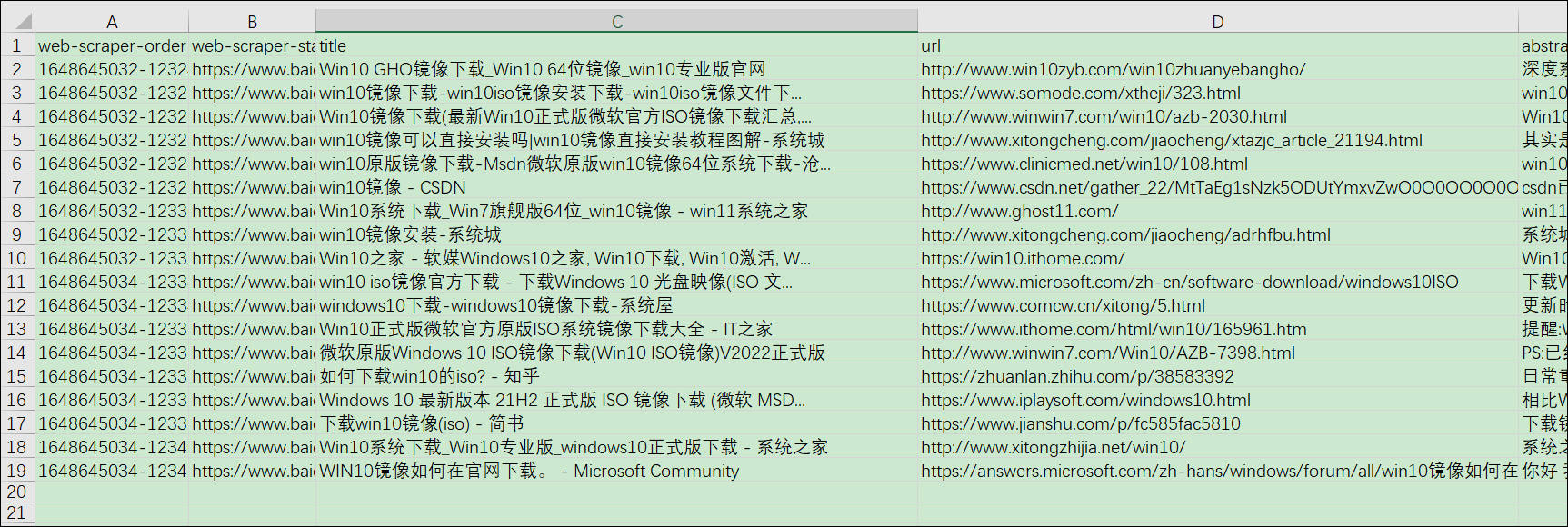
抓取的最终结果如下(只提取了2页):
如果你感兴趣的话,永恒君把整个sitemap文件放在了公号后台,后台回复「百度」,付费获取的~~
另外,之前写过的关于webscraper的文章教程和实例可以查看这里:http://www.yhjbox.com/category/webscraper
