
大家好,我是爱分享的永恒君!
之前分享过如何来快速搜集百度搜索的结果,文章在这里:
最近刚好也需要对百度知道进行数据搜集,今天的文章就来分享一下关于快速搜集百度知道的数据。
还是老规矩,如下图,比方说我要提取搜索结果的标题、提问内容、URL链接、回答等一系列的信息。
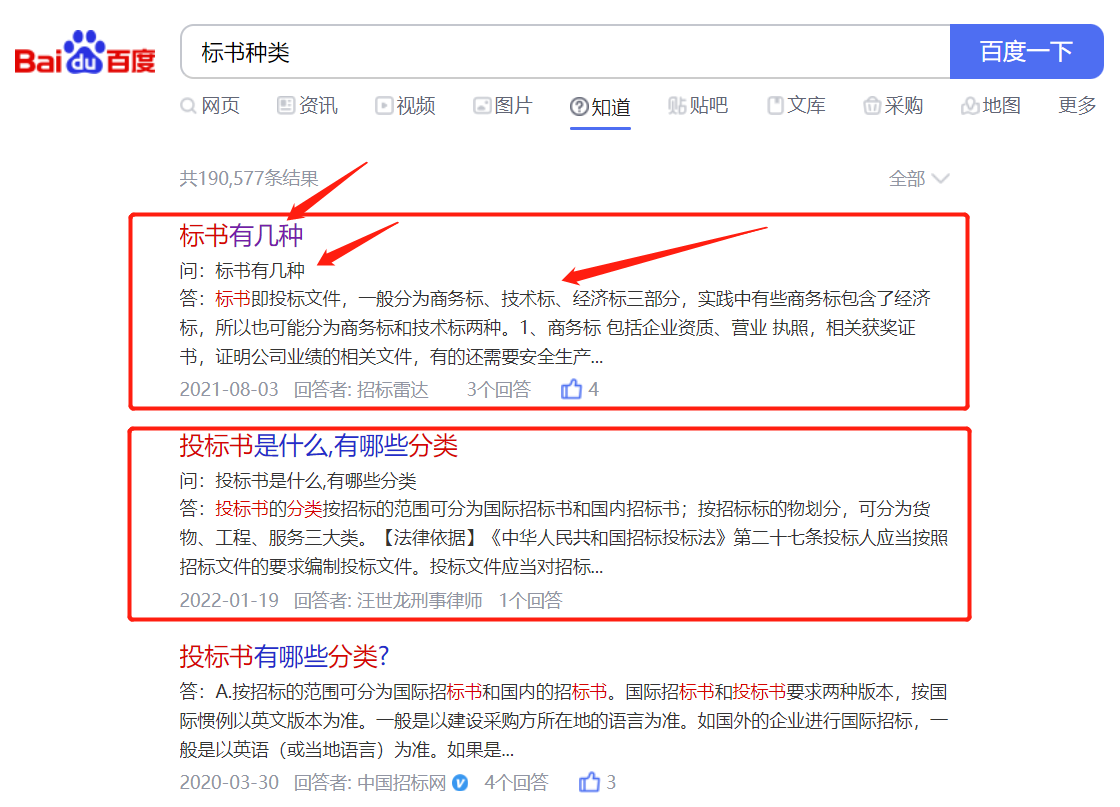
直接用web scraper就可以很快实现,方法很简单,直接用新建一个eliment选择器,然后,再把所有需要抓取的内容分别放在这个选择器下面即可。
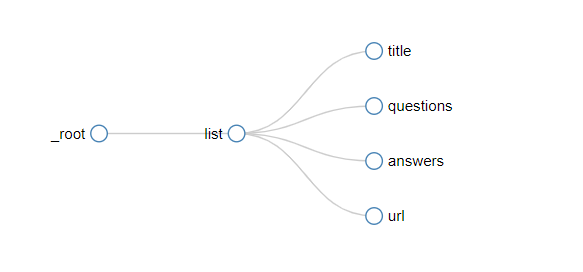
到这里其实都比较容易。
比较容易忽略的一点就是,如果需要处理翻页的话,其实不太建议用翻页器的方法,比较麻烦,而且不能控制页数。
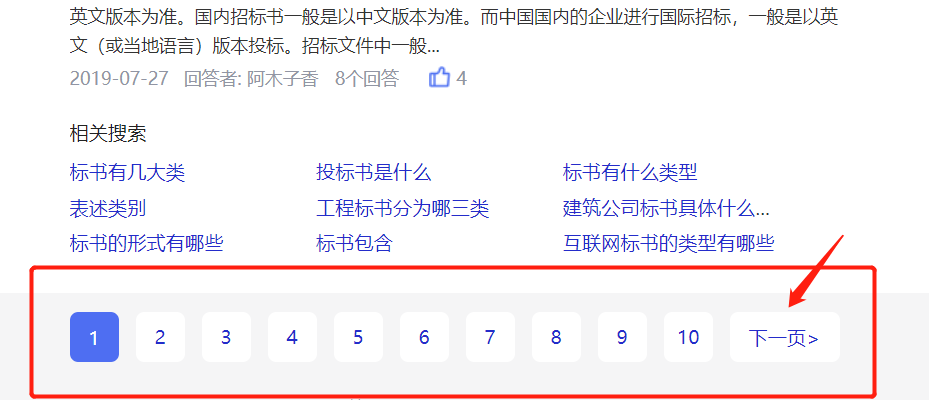
推荐使用下面这种的起始页链接,
https://zhidao.baidu.com/search?word=标书&dyTabStr=MCwzLDYsNSw0LDEsMiw4LDcsOQ==&pn=[0-10:10]
# “word=” 后面接搜索的关键词
#“pn=“ 后面接页面,以0起始,每隔10翻页
抓取2页后的最终结果如下:
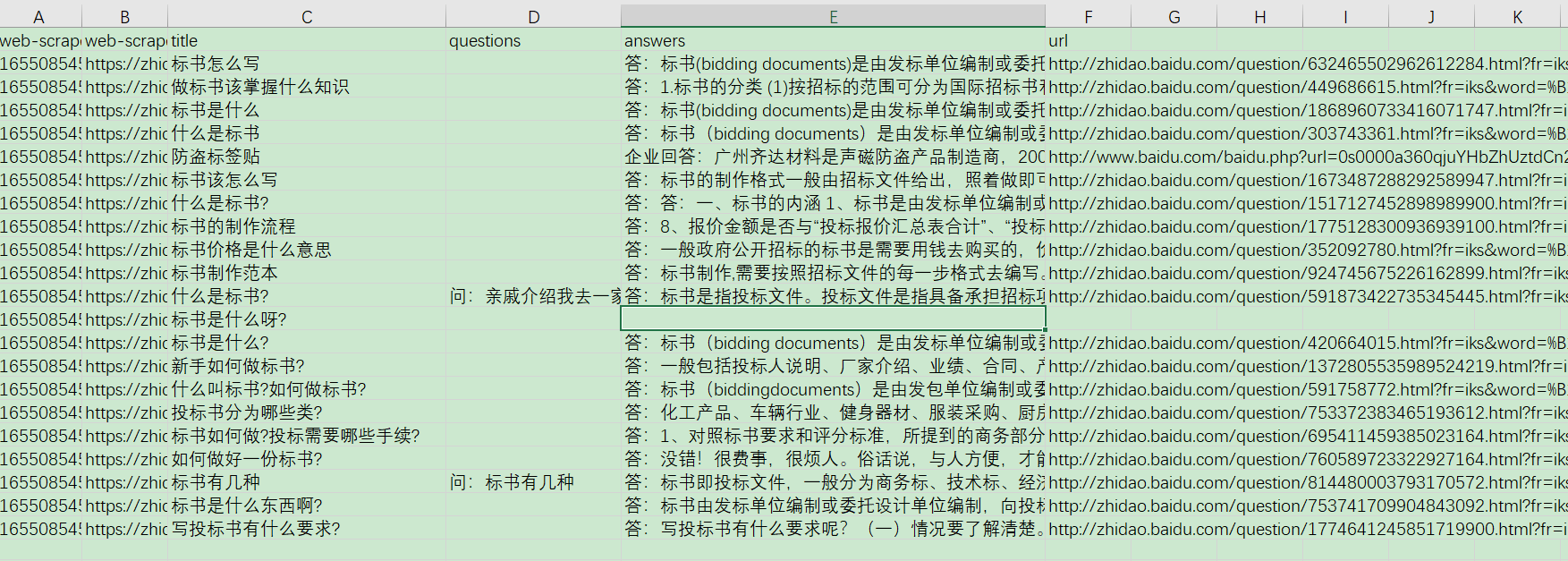
比较粗糙,其实还可以更精细一些,不过够用就行了。
以下就是完整的项目sitemap,感兴趣的可以试试~~
{"_id":"baiduzhidao","startUrl":["https://zhidao.baidu.com/search?word=%B1%EA%CA%E9&dyTabStr=MCwzLDYsNSw0LDEsMiw4LDcsOQ==&pn=[0-10:10]"],"selectors":[{"id":"list","parentSelectors":["_root"],"type":"SelectorElement","selector":"dl","multiple":true,"delay":0},{"id":"title","parentSelectors":["list"],"type":"SelectorText","selector":"a.ti","multiple":false,"delay":0,"regex":""},{"id":"questions","parentSelectors":["list"],"type":"SelectorText","selector":"dd.summary","multiple":false,"delay":0,"regex":""},{"id":"answers","parentSelectors":["list"],"type":"SelectorText","selector":"dd.answer","multiple":false,"delay":0,"regex":""},{"id":"url","parentSelectors":["list"],"type":"SelectorElementAttribute","selector":"a.ti","multiple":false,"delay":0,"extractAttribute":"href"}]}你可能还会想看:
写在最后
公众号运营至今,离不开小伙伴们的支持。
为了给大家提供一个相互交流的平台,特建立了一个交流群,交流学习摸鱼为主,不定时会分享一些效率提升的工具和学习资源,有一群有趣有料的小伙伴在等你哦!
进群方式:公众号后台回复888,按提示操作即可进群。
