实例讲解request库、bs4库的使用方法
之前写过一篇文章:分享|在线小说一键下载
文章里面简要的介绍一下使用python一键下载小说,该程序就是使用request库、bs4库完成的,比较适合入门的伙伴来学习。

正好之前介绍了python爬虫的一些知识,今天就来详细的说一下这个实例。
需求
爬取网页上小说的名字以及所有章节的内容,保存到txt文件。
以下面这篇
https://www.hongxiu.com/book/14088898305054404#Catalog
为例

思路
1、requests请求网页获得源代码;
2、bs4解析,从源代码中提取两个内容,一是作品的名字,二是提取各个章节的名字、链接;
3、再依次使用requests各个章节链接,bs4解析,提取每一章的内容;
4、将上面提取的数据保存到txt文件中。
代码实操
1、考虑内容有点多,将整体代码分块,方便编写和阅读,如下定义了四个函数。
def get_url_info(url):#request请求网页,bs4解析网页
def get_name(url):#获取小说名字
def get_catalog(url):#获取小说章节目录信息,包括1、章节名字,2、章节
def get_text(url):#获取小说章节正文
2、get_url_info()函数负责请求网页,解析网页,因为请求的次数比较多,专门编写一个调用,代码在python爬虫系列(3)- 网页数据解析(bs4、lxml、Json库)里面介绍过。
def get_url_info(url):#request请求网页,bs4解析网页
res = requests.get(url)
html = res.text
soup = bs(html, "lxml")
return soup
3、get_name(url)函数负责获取小说名字
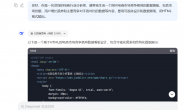
小说名字的源代码如下获取,可以看到是包裹在<h1>标签下的<em>标签,
通过.find_all("h1")[1].find("em").text即可提取到。

def get_name(url):#获取小说名字
soup = get_url_info(url)
name = soup.find_all("h1")[1].find("em").text
#获取小说名字,类型为list,取第二个后就转为str类型,此时获得的小说名字包含作者,如“一个人的外贸江湖 Tessly 著”
return name
因为上面定义了 get_url_info()函数,所以可以直接调用而不需要再写request那些代码。
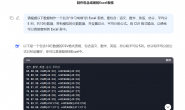
4、get_catalog()函数负责获取小说章节目录信息,包括章节名字和章节链接。根据上面的方法,同样可以查看到关于章节名字、链接的代码,如下:

包裹在<ul>标签下的<li>标签,通过
.find_all('ul')[3].find_all('li')将所有章节的信息先筛选出来,然后再用for循环,将每一章的名字、链接都提取出来,保存在catalog列表当中。
def get_catalog(url):#
soup = get_url_info(url)
catalog_data = soup.find_all('ul')[3].find_all('li') #所有章节的信息
catalog = []
for i in catalog_data:
data = {
"title":i.text,#章节名字
"link":"http:"+i.find('a').get('href')#章节链接
}
catalog.append(data)
return catalog
5、get_text()函数负责获取小说章节正文,通过步骤4获取到了每一章节的链接后,就可以提取里面的文章内容了。
文章代码如下:

正文是包裹在class_="read-content j_readContent"的<div>标签下,用.find_all('div',class_="read-content j_readContent")[0].text方法直接获取。
def get_text(url):#获取小说章节正文
soup = get_url_info(url)
novel = soup.find_all('div',class_="read-content j_readContent")[0].text
novel = '\n '+'\n\n '.join(novel.split()) #为了美观排版用
return novel
6、最后主程序直接调用上面的函数,就可以提取到所需要的文章信息,再直接写入txt文件就大功告成了。
写入文件用with open.write方法。
try...except...是目的是用来防止程序出错就挂掉而不运行下去了。
if __name__ == '__main__':
name = get_name(start_url)#小说名字
print("稍等,正在准备下载...")
print("保存路径为下载程序所在的目录:"+name+'.txt')
for chapter in get_catalog(start_url):
try:
with open(name+'.txt','a+') as f:#写入本地txt,文件名就是小说的名字
print("正在下载:"+chapter["title"])
f.write(get_name(start_url)+'\n\n')#写入小说名字
f.write(chapter["title"]+'\n')#写入章节名字
f.write(get_text(chapter["link"])+'\n') #写入章节内容
f.write('\n=====================分割线====================\n\n')
except:
pass
print("下载完成")
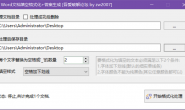
把上面步骤1-6组合起来就可以实现一键下载小说的效果了:

小结要点
1、request请求网页,主要就是requests.get()方法;
2、bs4解析网页,提取网页数据,主要运用了.find_all()方法;
3、网页的基本结构,如标签、属性等;
4、定义函数、for循环、列表、字典等python基本知识。
完整代码
import requests
from bs4 import BeautifulSoup as bs
start_url = input("请输入你要下载的文章链接:")+"#Catalog"
def get_url_info(url):#request请求网页,bs4解析网页
res = requests.get(url)
html = res.text
soup = bs(html, "lxml")
return soup
def get_name(url):#获取小说名字
soup = get_url_info(url)
name = soup.find_all("h1")[1].find("em").text
#获取小说名字,类型为list,取第二个后就转为str类型,此时获得的小说名字包含作者,如“一个人的外贸江湖 Tessly 著”
return name
def get_catalog(url):#获取小说章节目录信息,包括1、章节名字,2、章节链接
soup = get_url_info(url)
catalog_data = soup.find_all('ul')[3].find_all('li')
catalog = []
for i in catalog_data:
data = {
"title":i.text,#章节名字
"link":"http:"+i.find('a').get('href')#章节链接
}
catalog.append(data)
return catalog
def get_text(url):#获取小说章节正文
soup = get_url_info(url)
novel = soup.find_all('div',class_="read-content j_readContent")[0].text
novel = '\n '+'\n\n '.join(novel.split())
return novel
if __name__ == '__main__':
name = get_name(start_url)#小说名字
print("稍等,正在准备下载...")
print("保存路径为下载程序所在的目录:"+name+'.txt')
for chapter in get_catalog(start_url):
try:
with open(name+'.txt','a+') as f:#写入本地txt,文件名就是小说的名字
print("正在下载:"+chapter["title"])
f.write(get_name(start_url)+'\n\n')
f.write(chapter["title"]+'\n')
f.write(get_text(chapter["link"])+'\n')
f.write('\n=====================分割线====================\n\n')
except:
pass
print("下载完成")
input("按任意键退出")
当然,如有需要打包好的程序和代码,直接在微信公号后台回复「小说」即可!
爬虫系列:
python爬虫系列(4)- 提取网页数据(正则表达式、bs4、xpath)
python爬虫系列(3)- 网页数据解析(bs4、lxml、Json库)
python实例:
用python定制网页跟踪神器,有信息更新第一时间通知你(附视频演示)
微信公众号:永恒君的百宝箱
个人博客:www.yhjbox.com