
 要制作词云呢,需要有一定数量的
要制作词云呢,需要有一定数量的关键词,以及权重值(或者出现频率)。而要得到这些关键词、权重值,必须要有一定量的内容信息,总不能我们自己瞎编瞎写吧~~
那今天就来和大家分享一下永恒君的整个操作过程,希望对大家能有启发和帮助。
1、获取内容信息
这一步是基础,获取的方式有很多样,但无外乎就是两类
- 直接内容,如给学生调查问卷,整理成稿
- 间接内容,如网上搜集相关资料文章、相关问答
永恒君采取的是第二种,直接从知乎上面找到相关内容的高赞回答的问题,然后将该问题的所有答案都抓取下来。
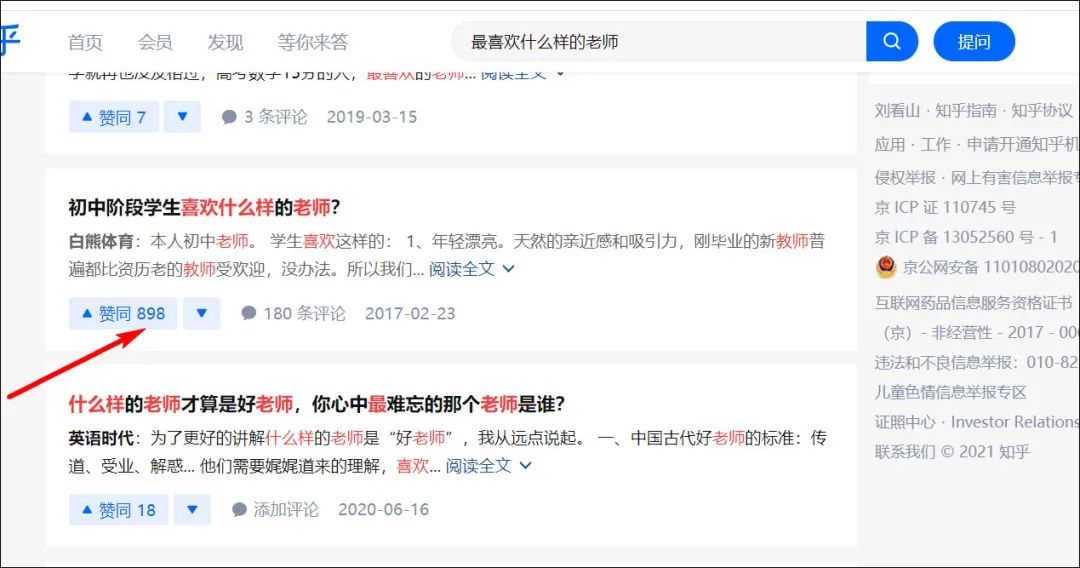
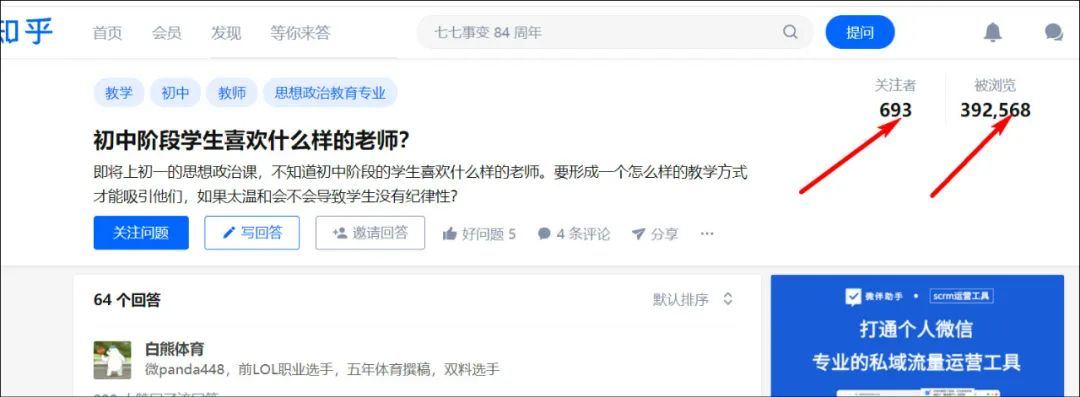
如这个问题,相关性就比较高,浏览量和回答人数也还算可以。(当然你也可以选择其他你认为更合适的问题。)
接下来就要使用我们的web scraper来抓取数据了,配置很简单,主要就是配置Element Scroll down就好了。
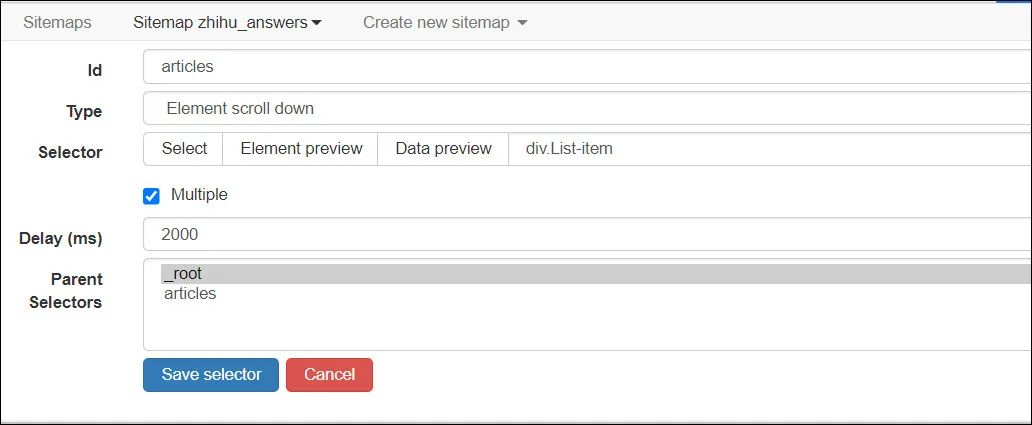
抓取到的数据,经过整理得到想要的回答内容如下:

将上述抓取到的数据内容保存到goodteacher.txt备用,这样我们就得到了最重要的基础数据。
2、获取关键词和权重(词频)
这一步需要有一点编程的能力,永恒君这里使用python的jieba库,
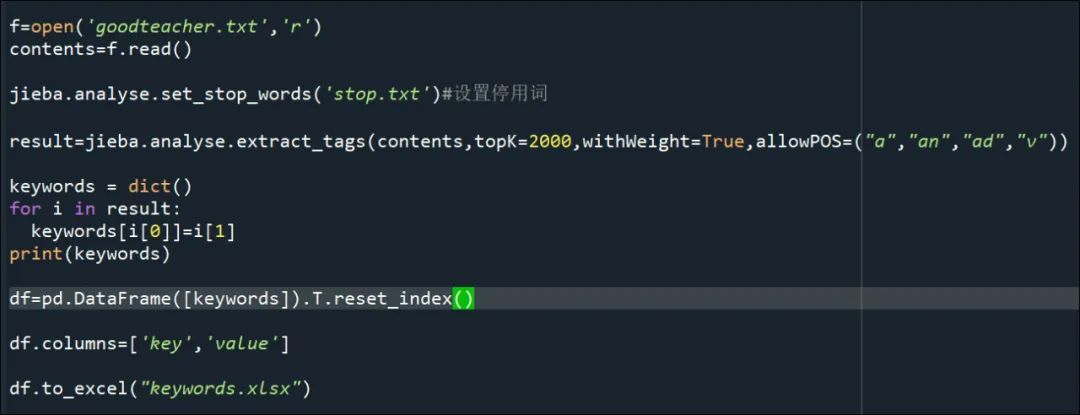
提取goodteacher.txt内容的动词、形容词之后,经过简单的统计整理,生成keywords.xlsx,得到如下的结果:
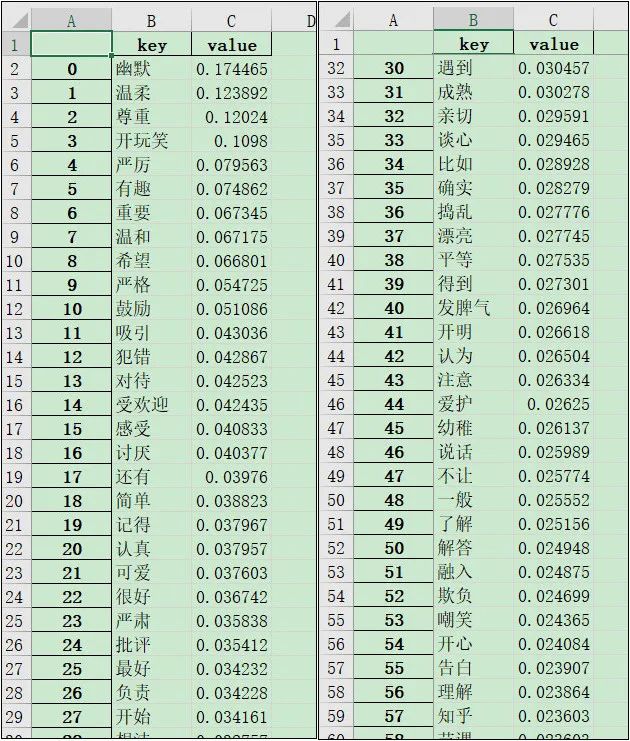
当然,这其中还包含了一些无效、或者对主题无意义的词,可以按需求进行适当的修改。
3、生成词云
有了上述的关键词文件keywords.xlsx之后,生成词云的方式就有很多了,网上能搜到许多的在线词云网站,但是一般都会有这样那样的限制,感觉不方便。
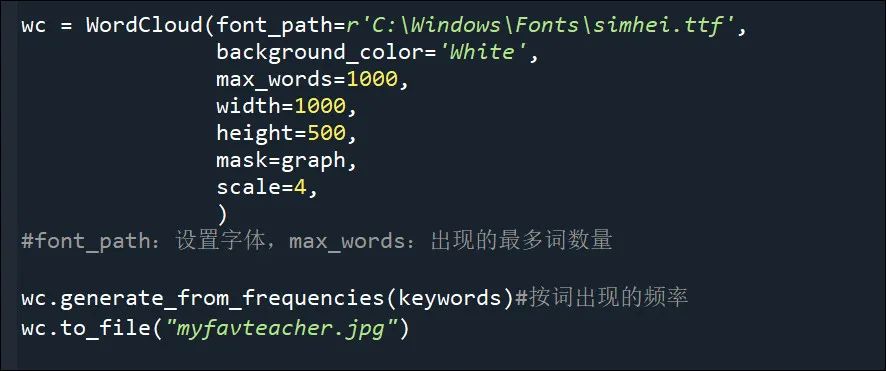
永恒君这里依然使用的是python,通过调用wordcloud库,可以非常方便的生成想要的词云,没有这样那样的限制。
最后生成的两种词云图如下:


可以看到,初中学生喜欢的老师大致画像是幽默、温柔、尊重人、能开玩笑、有趣等等。
其中温柔排这么前,是否说明现在的初中女老师居多呢?

你可能还会想看: