“一起去爬山吧?”
这句台词火爆了整个朋友圈,没错,就是来自最近热门的《隐秘的角落》,豆瓣评分8.9分,好评不断。
永恒君趁着端午的假期也赶紧刷完了这部剧,感觉还是蛮不错的。同时,为了想更进一步了解一下小伙伴观剧的情况,永恒君抓取了爱奇...
6年前 (2020-06-30) 2153℃ 0评论
作者 | 刘早起来源 | 早起Python
大家好,儿童节就要来了,虽然秃头程序员没有头发,但是童心还是一直都在的,今天就分享一个私藏的GitHub项目——free-python-games,一行代码就能进入使用Python开发的小...
6年前 (2020-06-01) 2257℃ 0评论
上一篇文件用VBA介绍了如何实现一键按列分类汇总并保存单独文件,代码有几十行,而且一旦数据量多了,效果可能不尽如人意。
文章可以参见这里:vba实例(27)-一键按列分类汇总并保存单独文件
今天就来给大家说说如何用python来实现这个效果...
6年前 (2020-05-19) 3021℃ 0评论
今天一位粉丝的需求所涉及的问题值得和大家分享分享~~~
背景问题
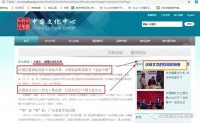
是这样的,他看了公号里的关于web scraper的系列文章后,希望用它来爬取一个网站搜索关键词后的文章标题和链接,如下图
按照教程,复制网页地址、写选择器、运行调试,发现...
6年前 (2020-02-27) 2257℃ 0评论
周末有位网友询问永恒君,因为工作的原因,经常会在某一些网站查找关键词,然后截图。任务简单,但是很繁琐,有时候数量也比较大,希望指点一下思路可以解决这个问题。
这个用python的selenium库就可以很好的解决浏览器的操作自动化问题。
简...
7年前 (2019-12-17) 2223℃ 0评论
将永恒君的百宝箱设为星标 精品文章第一时间读
实例讲解request库、bs4库的使用方法
之前写过一篇文章:分享|在线小说一键下载
文章里面简要的介绍一下使用python一键下载小说,该程序就是使用request库、bs4库完成的,...
7年前 (2019-08-19) 3006℃ 0评论
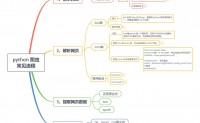
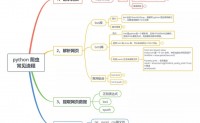
python爬虫系列(4)- 提取网页数据(正则表达式、bs4、xpath)
python 爬虫 常见流程.jpg
记录提取网页数据(正则表达式、bs4、xpath)一些常用方法和使用样板。
就永恒君使用经验来说,bs4、xpath比较容易...
7年前 (2019-08-12) 2381℃ 0评论
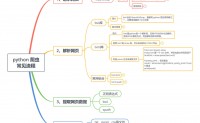
python爬虫系列(3)- 网页数据解析(bs4、lxml、Json库)
python 爬虫 常见流程.jpg
本文记录解析网页bs4、lxml、Json一些常用方法和使用样板
简介
通过requests库向网站请求网页,获得网页源代码之...
7年前 (2019-08-05) 2465℃ 0评论
记录requests库中的get使用方法以及使用样板
介绍
requests 是一个功能强大、简单易用的 HTTP 请求库,详细的就不多介绍了,总之是大名鼎鼎,请求网页最常用的一个库。
官方文档网址:http://cn.python-req...
7年前 (2019-07-30) 2469℃ 0评论
事由
之前间断地写过一些python爬虫的一些文章,如:
工具分享 | 在线小说一键下载
Python帮你定制批量获取智联招聘的信息
Python帮你定制批量获取你想要的信息
用python定制网页跟踪神器,有信息更新第一时间通知你(附视频...
7年前 (2019-07-29) 2175℃ 0评论